Texte an der Konsole ausgeben mit dem Ausgabeobjekt cout
Vorläufig werden wir cout einfach verwenden, ohne seine Funktionsweise vollständig zu verstehen. Um einen Wert auf dem Bildschirm auszugeben, musst du cout eingeben, gefolgt von dem Umleitungsoperator (<<), den man durch zweimaliges Betätigen der [<]-Taste erzeugt. Auch wenn es sich hier um zwei Zeichen handelt, werden sie von C++ als ein Symbol interpretiert. Im Anschluss an den Umleitungsoperator gibst du deine auszugebenden Daten ein. Das folgende Listing soll dir die Anwendung demonstrieren. Gib das folgende Beispiel wortgetreu ein, nur das du anstatt des Namens Micha B. deine eigenen Namen eintippst (es sei denn, du bist ich).
// Listing 'coutdemo.cpp' zeigt die Verwendung von cout
#include <iostream>
using namespace std;
int main()
{
cout << "Hallo dort.\n";
cout << "Hier ist 5: " << 5 << "\n";
cout << "Der Manipulator endl beginnt eine neue Zeile.";
cout <<
endl;
cout << "Hier ist eine große Zahl:\t" << 70000 << endl;
cout << "Hier ist die Summe von 8 und 5:\t" << 8+5 << endl;
cout << "Hier ist ein Bruch:\t\t" << (float) 5/8 << endl;
cout << "Und eine riesengroße Zahl:\t";
cout << (double) 7000 * 7000 <<
endl;
cout << "Vergiss nicht, Micha B. durch deinen Namen"
" zu ersetzen...\n";
cout << "Micha B. ist ein C++-Programmierer!\n";
return 0;
}
Ausgabe:
./coutdemo
Hallo dort.
Hier ist 5: 5
Der Manipulator endl beginnt eine neue Zeile.
Hier ist eine große Zahl: 70000
Hier ist die Summe von 8 und 5: 13
Hier ist ein Bruch: 0.625
Und eine riesengroße Zahl: 4.9e+07
Vergiss nicht, Micha B. durch deinen Namen zu ersetzen...
Micha B. ist ein C++-Programmierer!
Erklärungen:
Zeile 1 enthält einen einzeiligen Kommentar, welcher den Zweck des Programms erklärt.
Zeile 2 bindet mit der Anweisung #include<iostream> die Datei IOSTREAM in die Quellcode-Datei ein. Dies ist erforderlich, um cout und die verwandten Funktionen verwenden zu können.
Zeile 4 legt den Namensraumstd fest, in welchem cout definiert ist. Würdest du diese Anweisung weglassen, dann müsstest du im Quelltext die Anweisung um std::cout erweitern, anstatt einfach nur cout zu schreiben.
Zeile 8 gibt einen Text und einen Zeilenvorschub mittels \n (newline) aus.
In Zeile 9 werden cout drei Werte übergeben, wobei die Werte voneinander durch einen Umleitungsoperator getrennt werden. Der erste Wert ist der String „Hier ist 5:“ Beachte das Leerzeichen nach dem Doppelpunkt. Dieser Raum ist Teil des Strings. Anschließend wird dem Umleitungsoperator der Wert 5 und das Zeichen für „Neue Zeile“ ( „\n“ für newline, immer in doppelten oder einfachen Anführungszeichen) übergeben. Damit wird insgesamt folgende Zeile
Hier ist 5: 5
auf dem Bildschirm ausgegeben. Da hinter dem ersten String kein „Neue Zeile“-Zeichen kommt, wird der nächste Wert direkt dahinter ausgegeben. Dies nennt man auch »die zwei Werte verketten« (Konkatenation).
Zeile 10 gibt eine Meldung aus und in Zeile 11 wird dann dann der Manipulator endlverwendet. Sinn und Zweck von endl ist es, eine neue Zeile auf dem Bildschirm auszugeben. Damit bewirkt dieser Manipulator dasselbe, als wenn du \n(newline) verwendet hättest – endl steht für end line (Ende der Zeile).
Zeile 14 führt ein neues Formatierungszeichen, das \t, ein. Damit wird ein Tabulatorschritt eingefügt, mit dem die Ausgaben der Zeilen 14 bis 17 bündig ausgerichtet werden. Zeile 14 zeigt auch, dass nicht nur der DatentypInteger, sondern auch Integer vom Typ long ausgegeben werden können. Zeile 15 zeigt, dass cout auch einfache Additionen verarbeiten kann. Der Wert 8+5 wird an cout weitergeleitet und dann als 13 ausgegeben.
In Zeile 16 wird cout der Wert 5/8 übergeben. Mit dem Begriff (float) teilen Sie cout mit, dass das Ergebnis als Dezimalzahl ausgewertet und ausgegeben werden soll. In Zeile 18 übernimmt cout den Wert 7000 * 7000. Der Begriff (double) teilt cout mit, dass du diese Ausgabe in wissenschaftlicher Notation wünschst. Diese Themen werden wir noch im Detail im Kapitel »Variablen und Konstanten« im Zusammenhang mit den Datentypen besprechen.
In Zeile 23 hast du meinen mit deinem Namen ersetzt und der Computer nennt dich einen C++-Programmierer. 😉
Anmerkung:Über den Sinn und Zweck von Kommentaren haben wir ja bereits gesprochen. Kommentare, die beschreiben, was eh schon jeder sieht, sind nicht besonders sinnvoll. Sie können sogar kontraproduktiv sein, wenn sich der Code ändert und der Programmierer vergißt, den Kommentar mit zu ändern. Aber was für den einen offensichtlich ist, ist für andere undurchsichtig. Deshalb ist sorgfältiges Abwägen gefragt.
Zu guter Letzt möchte ich noch anmerken, dass Kommentare nicht mitteilen sollten, was du machst, sondern warum du es machst.
Programme sind besser lesbar und auch nach langer Zeit noch nachvollziehbar, wenn du den Quellcode sinnvoll kommentierst. Außerdem kann es bei der Entwicklung umfangreicherer Programme manchmal sinnvoll bei der Fehlersuche sein, bestimmte Bereiche vorübergehend auszukommentieren. Das funktioniert, weil der Compiler Kommentare bei der Übersetzung eines Programms schlichtweg überliest und deren Inhalt ignoriert. C++ kennt zwei Arten von Kommentaren, die beide ihren Anwendungsbereich und ihre Vorteile haben.
’Oldstyle’ C Kommentare
Es gibt sie schon seit den Zeiten der Programmiersprache C. Man bezeichnet sie auch als mehrzeilige Kommentare, weil alles, was zwischen der einleitenden Zeichenkombination /* und der abschließenden Zeichenkombination */ steht, vom Compiler ignoriert wird. Trotzdem können sie auch als einzeilige Kommentare verwendet werden, wenn beide Kombinationen auf der gleichen Zeile zur Anwendung kommen. Beispiele:
/*
Ich bin ein mehrzeiliger Kommentar im 'alten' Stil von ANSI C.
Der Compiler ignoriert mein Geschwätz.
*/
/* Ich bin ein mehrzeiliger Kommentar, der wie ein Einzeiliger tut. */
’Newstyle’ C++ Kommentare
Sie sind einzeilig und typisch für C++. Alles, was innerhalb der selben Zeile hinter der Zeichenkombination // steht, wird vom Compiler ignoriert. Typische Anwendungsfälle sind Beschreibungen hinter einer Anweisung oder das Auskommentieren einzelner Zeilen. Beispiele:
// ich bin ein einzeiliger Kommentar! Der Compiler ignoriert mein Geschwätz.
int i = 42 // Deklaration einer Integer-Variablen
// 'z' wird auskommentiert:
// int z = 4711;
Das Verschachteln von Kommentaren ist in C und C++ verboten:
/*
Alle meine Entchen!
/* Verboten: Ein verschachtelter Kommentar innerhalb eines Kommentars */
*/
Anmerkung:Kommentare, die beschreiben, was eh schon jeder sieht, sind nicht besonders sinnvoll. Sie können sogar kontraproduktiv sein, wenn sich der Code ändert und der Programmierer vergisst, den Kommentar mit zu ändern. Aber was für den einen offensichtlich ist, ist für andere undurchsichtig. Deshalb ist sorgfältiges Abwägen gefragt.
Zu guter Letzt möchte ich noch anmerken, dass Kommentare nicht mitteilen sollten, was du machst, sondern warum du es machst.
Quelltext-Regeln und Formatierung
C++ ist eine formatfreie Sprache. Das bedeutet, dass du bei der optischen Gestaltung deiner Quelltexte mit wenigen Einschränkungen völlig frei bist. Nehmen wir einmal an, du hättest unser erstes Programm auf diese Art notiert:
#include
<iostream>
int
main() {
std::cout << "Hallo vom langweiligsten Programm der Welt!"
<< std::endl;
return 0;
}
Unübersichtlich, nicht wahr? Trotzdem ist der Quellcode aus Compilersicht legal und wird auch anstandslos übersetzt. Ob diese Art der Formatierung für das menschliche Auge angenehm und leicht lesbar ist, bedarf vermutlich keiner Diskussion.
Es existieren viele unterschiedliche Stile und Empfehlungen bezüglich der Quellcodeformatierung. Grundsätzlich sollte der Quellcode auf jeden Fall leicht lesbar und auf eine nachvollziehbare Strukturierung aufgebaut sein. Wenn du erst einmal einen persönlichen Stil entwickelt hast, der diesen Anforderungen gerecht wird – behalte ihn möglichst konsequent bei. Es wird dir auch nach Jahren noch das Verständnis für deinen Code enorm erleichtern. Hier einige Tipps:
Rücke zusammengehörige Anweisungsblöcke und Bedingungsabfragen immer ihrer Logik nach ein. Schreibe dazu zusammengehörige Klammern stets untereinander und verwende Tabulatorsprünge, um deren Inhalte sichtbar als zugehörig zu kennzeichnen.
Verwende Leerzeilen zwischen Funktionen und thematisch abgeschlossenen Bereichen.
Achte auf die Zeilenlänge deiner Anweisungen – was auf einem hochauflösenden Monitor noch gut aussieht, kann auf dem Drucker ein Desaster sein. Beschränke dich auf bummelig 90 Zeichen pro Zeile und brich längere Zeilen unter Berücksichtigung syntaktischer Regeln um (siehe ‚Zeilenfortsetzung‘ im Abschnitt über den Syntax von C++).
Verwende, wo immer nötig, Kommentare, um dein Programm nachvollziehbar zu halten. Ein Beispiel:
/*
* Das Einsteigerseminar C++
*
* hallo2.cpp
* Das wohl langweiligste Programm der Welt, Version 2
*/
#include <iostream> // Ein-/Ausgabebibliothek einbinden
using namespace std; // Namensraum 'std' (Standard) einbinden
int main()
{
// Lange Zeichenkette aufteilen mit '\':
cout << "Das langweiligste Programm der Welt " \
"meldet sich zurueck mit einer sehr, " \
"sehr langen Zeichenkette!\n"
<< endl;
// Zwei Zeichenketten nacheinander über zwei Zeilen ausgeben:
cout << "Was ich noch sagen wollte:"
<< endl
<< "C++ macht Laune."
<< endl;
return 10; // Gib den Wert 10 zurück an den Aufrufer
}
Syntax-Regeln für die Sprache C/C++
Die Programmiersprache C/C++ beinhaltet gleich mehrere Sprachen/ Syntaxen:
C-Syntax
Präprozessor-Syntax
Printf/Scanf Formatstring Syntax
Terminal Emulation
Compiler/Linker Anweisungen
In diesem Kapitel sollen zunächst nur allgemeine Eigenschaften der Sprache, der grundlegende Syntax und die Kontrollstrukturen erklärt werden. Bei vielen Erklärungen sind Code-Beispiele vorhanden. Vieles, was du hier zu lesen bekommst, wirst du erst im weiteren Verlauf des Tutorials vollständig verstehen – trotzdem ist es wichtig, von den einzelnen Begrifflichkeiten mal gehört zu haben.
Da man aus Fehlern am meisten lernt, sind zum Teil auch negative Beispiele enthalten. Für ein besseres Verständnis empfiehlt es sich, Code-Beispiele selbst nachzuvollziehen.
Zeichensatz:
Der Syntax von C nutzt die unteren 128 Zeichen des ASCII Zeichensatzes. Da UTF-8 in den ersten 128 Zeichen deckungsgleich zu ASCII ist, kann auch dieser zur Erstellung des Source Codes genutzt werden. Zeichen außerhalb dieses gültigen Zeichensatzes können folglich nur in Strings oder Kommentaren vorkommen. Tatsächlich empfiehlt sich die Verwendung eines auf UTF-8 kodierten Zeichensatzes, da dieser bei der Übernahme eines Quelltexts zwischen verschiedenen Betriebssystemen kaum Probleme aufwirft.
Namenskonventionen
Folgende Regeln gelten bzgl. der Benennung von Variablen und Funktionen:
Variablen und Funktionsnamen können aus Buchstaben, Zahlen und dem Unterstrich bestehen. Sie müssen mit einem Buchstaben oder einem Unterstrich beginnen
C/C++ ist Case sensitiv, d.h. es wird zwischen Groß- und Kleinbuchstaben unterschieden
Schlüsselwörter können nicht für Variablen/Funktionsnamen/Datentypen genutzt werden Namenskonventionen von Library-Funktionen:
In C (und C++) sind Schlüsselwörter und Standardlibrary-Funktionen zumeist in Kleinbuchstaben geschrieben. In der C-Standardlibrary werden oftmals verkürzte Ausdrücke wie z.B. isalnum() (zum Testen ob ein Zeichen ein Buchstaben oder ein Digit ist) und in C++ der Unterstrich als Worttrenner (z.b. out_of_range) genutzt.
Makros werden per Konvention in GROSSBUCHSTABEN und ggf. mit Unterstrich als Worttrenner geschrieben.
Namen beginnend mit doppelten Unterstrich oder beginnend mit einem Unterstrich gefolgt von einem Großbuchstaben (z.B. __LINE__ _Reserved) sind für den Compiler und der Standard-C-Library vorbehalten und sollten im eigenen Programm nicht benutzt werden.
Zeilenfortsetzung
Mit dem Backslash Operator (gefolgt von einem Zeilenende) kann eine Zeile in der nächsten Zeile fortgesetzt werden. Der Compiler löscht das \-Zeichen mit anschließendem Zeilenende und ersetzt dies durch nichts. Dies ist insbesondere bei Anweisungen notwendig, die am Ende der Zeile abgeschlossen sein müssen (z.B. Strings, Makros).
Beispiele:
char str1[]="Strings müssen am Ende per Anführungszeichen abgeschlossen sein
so dass dies ein Fehler ist";
char str2[]="Dies\
ist ein Test"; //Vorsicht, führende Leerzeichen vor 'ist'
//bleiben erhalten!
/*mehrzeiliges Makro*/
#define MAX(a,b) (a>b?\
b: \
a)
//Dies ist ein Zeilenkommentar \
welcher in dieser Zeile fortgesetzt wird
/\
* dies ist ein Blockkommentar*\
/
//hinter der Zeilenfortsetzung darf nur ein CR/LF folgen
#define MAX2(a,b) \ //so dass hier kein Kommentar folgen darf
a>b?a:b
Hinweis:
Innerhalb von Char-Literatoren und Strings wird ‚\‘ als Escape-Operator genutzt, welche das ‚\‘ und ein oder mehrere folgende Zeichen ersetzt. Daher darf hinter Backslash als Zeilenfortsetzungszeichen kein weiteres Zeichen folgen.
Gültigkeit und Sichtbarkeit von Variablen
Vorrangig in der objektorientierten Programmierung werden mit Namensräumen Objekte und deren Methoden/Attribute in einer Art Baumstrukturstrukturiert. Dies ermöglicht eine eindeutige Ansprache von Variablen/Objekte, aber auch eine doppelte Verwendung von Methoden-/Attributnamen in unterschiedlichen Namensräumen. Ergänzend zu den Namensräumen kann mit public/private/proteced eine Zugriffsbeschränkung von Methoden/Attributen definiert werden.
Die Programmiersprache Cunterstützt keinen Namensraum. Zugriffsmodifikatoren werden indirekt über Header-Dateien getätigt. Hinsichtlich der Gültigkeit/Sichtbarkeit unterscheidet C folgende Bereiche:
Funktionen (Function Scope)
Datei (File Scope)
Block (Block Scope)
Funktionsparameter in Prototypen (Function Prototype Scope)
Innerhalb eines Gültigkeitsbereiches dürfen Variablen-/Funktions-/Datentypnamen nicht doppelt genutzt werden. In der Programmiersprache C++ sind weitere Scope wie z.B. Class Scope, Enumationation Scope und ergänzend das Konzept von Namensräumen vorhanden (Beschreibung folgt).
Funktionsweite Sichtbarkeit
Eine Label-Definition (als Sprungmarke für die goto-Anweisungen) erfolgt immer mit funktionsweiter Sichtbarkeit/Gültigkeit.
Dateiweite Sichtbarkeit
Erfolgt eine Funktion-/Variablen-/Datentyp-Definition außerhalb eines Block-Scopes oder von Funktionsparameter, so sind diese innerhalb der gesamten Datei und bei Funktionen/Variablen ergänzend Projektweit (für alle Objektdateien) sichtbar/gültig (= global). Alle globalen Funktionen/Variablen können von allen Dateien aus genutzt/zugegriffen werden (sofern sie zuvor deklariert wurden). Beispiel 1:
// Deklaration von func(),
// welche in Datei2.c definiert wird
extern void func(void);
// Definition der Variablen global
int global=0;
int main(void)
{
func();
global++;
return 0;
}
Beispiel 2:
// Deklaration von global,
// welche in Datei1.c definiert wird
extern int global;
// Definition der Funktion func()
void func(void)
{
global++;
}
Wird das Schlüsselwort ’static‘ der Variablen/Funktionsdefinition vorangestellt, so wird die Sichtbarkeit/Gültigkeit auf Dateiweit eingeschränkt. Variablen/Funktionen können nur innerhalb der (Objekt-) Datei genutzt werden und sind für anderen (Objekt-)Dateien unsichtbar.
Beispiel 1:
// Dateiweite Sichtbarkeit von var1
static int var1;
int main(void)
{
var1++;
return 0;
}
Beispiel 2:
// Dateiweite Sichtbarkeit von var1
static int var1;
void func(void)
{
static int var2; // Vorsicht, static
// hat hier eine andere Bedeutung
var1++;
}
Projektweite Gültigkeit
bedeutet insbesondere, dass keine doppelten Benennung von Variablen/Funktionen/Datentypen innerhalb des gesamten Projektes erlaubt sind, d.h. dass alle Variablen/Funktionennamen über alle Dateien/Librarys eindeutig sein müssen. Beispiel 1:
Datei 1:
// datei_1.cpp
#include <stdio.h>
int a=1;
int main(int argc,char *argv[])
{
printf("Hello World %d",a);
void dummy(void); //Deklaration von Dummy
dummy();
return 0;
}
Datei 2:
// datei_2.cpp
#include <stdio.h>
int a=7;
void dummy(void)
{
printf("Hello Again %d\n",a);
}
Versuche, die beiden Dateien zusammen zu compilieren:
g++ -Wall datei_1.cpp datei_2.cpp -o beipiel1
Der Linker meldet beim Zusammenfügen der Objekt-Dateien, dass die Variable a bereits woanders definiert sei (multiple definition of ‚a‘):
gcc -Wall datei1.cpp -o beispiel1
datei_1.cpp:4:5: Fehler: Redefinition von »int a«
4 | int a=1;
| ^
In Datei, eingebunden von datei_1.cpp:3:
datei_2.cpp:3:5: Anmerkung: »int a« wurde bereits hier definiert
3 | int a=7;
| ^
Hier meldet der Compiler eine Fehlermeldung, da das Symbol printf zum einen als Variable und zum anderen als Funktion (innerhalb der inkludierten Datei stdio.h beschrieben) genutzt wird (‚printf‘ redeclared as different kind of symbol):
g++ -Wall beispiel2.cpp
beispiel2.cpp:2:5: Fehler: »int printf« als andere Symbolart redeklariert
2 | int printf=7;
| ^~~~~~
In Datei, eingebunden von beispiel2.cpp:1:
/usr/include/stdio.h:356:12: Anmerkung: vorherige Deklaration von »int printf(const char*, ...)«
356 | extern int printf (const char *__restrict __format, ...);
| ^~~~~~
beispiel2.cpp: In Funktion »int main()«:
beispiel2.cpp:5:12: Warnung: Format »%d« erwartet Argumenttyp »int«, aber Argument 2 hat Typ »int (*)(const char*, ...)« [-Wformat=]
5 | printf("%d\n", printf);
| ~^ ~~~~~~
| | |
| int int (*)(const char*, ...)
Blockweite Sichtbarkeit
Erfolgt eine Funktion-/Variablen-/Datentyp Definition innerhalb einer Funktion, als Funktionsparameter oder eines Blockes, so sind diese nur innerhalb des Blockes sichtbar/gültig (= Lokale Variable). Blöcke können verschachtelt sein, so dass das bei identischer Namensgebung innere Definitionen Vorrang haben. Ebenso haben Blockdefinitionen Vorrang vor Datei-/Projektdefinitionen (überdecken diese):
blockweit1.cpp
int main(void)
{
int var2; //var2 ist nur innerhalb
//von main() sichtbar
struct xyz //Datentyp ist nur innerhalb
{int x,y,z;};//von main()
//sichtbar/gültig
extern void func(void); //Deklaration
//ist nur innerhalb von
//main() sichtbar/gültig
func();
}
void foo(void) {
struct xyz var_xyz; //Fehler, da
//Datentypedefinition hier nicht mehr
//gültig ist!
func(); //Fehler, da Deklaration
//hier nicht mehr gültig ist
}
blockweit2.cpp
#include <stdio.h>
void func(void)
{
int var2=1; //var2 ist
//nur innerhalb von
//func() sichtbar
{
int var2=2;
//var2 ist nur innerhalb
//dieses Blockes sichtbar
printf("%d\n",var2);
}
printf("%d\n",var2);
}
Auch dieses aus zwei Dateien bestehende Programm wird vom Compiler angemeckert:
g++ -Wall blockweit1.cpp blockweit2.cpp -o blockweit
blockweit1.cpp: In Funktion »int main()«:
blockweit1.cpp:2:7: Warnung: Variable »var2« wird nicht verwendet [-Wunused-variable]
2 | int var2; //var2 ist nur innerhalb
| ^~~~
blockweit1.cpp: In Funktion »void foo()«:
blockweit1.cpp:14:13: Fehler: Aggregat »foo()::xyz var_xyz« hat unvollständigen Typ und kann nicht definiert werden
14 | struct xyz var_xyz; //Fehler, da
| ^~~~~~~
blockweit1.cpp:18:2: Fehler: »func« wurde in diesem Gültigkeitsbereich nicht definiert
18 | func(); //Fehler, da Deklaration
| ^~~~
Soviel zunächst zu Syntaxregeln in C/C++. Gräme dich nicht, wenn du gerade an ‚Bahnhof‘ und ‚Züge‘ denkst – wir werden im weiteren Verlauf des Tutorials an den jeweiligen Stellen wiederholend am praktischen Beispiel auf die Syntaxregeln eingehen.
In diesem Teil des C++ Tutorials beschäftigen wir uns mit Techniken zur Speicherung unserer Quelltexte und dem Schreiben und Übersetzen derselben. Bevor es richtig losgeht, noch einige Vorüberlegungen zur Organisation der anfallenden Daten:
Betrachte ab sofort jedes Programm, das du eingibst, als eigenständiges Projekt. Lege dir zu diesem Zweck zunächst ein Sammelverzeichnis an, in welchem du dann wiederum Ordner für die eigentlichen Projekte erstellst. Beispiel:D:\Einsteigerseminar
Jedes Projekt erhält seinen eigenen Ordner, in dem alle relevanten Daten zum Projekt gespeichert werden. Dies ist das Arbeitsverzeichnis des jeweiligen Projekts! Beispiel 1:D:\Einsteigerseminar\001_Hallo Beispiel 2:D:\Einsteigerseminar\002_Kommentare
Relevante Daten können z. B. sein:
C++-Quelltext für das eigentliche Programm (Suffix: .cpp)
C++-Quelltexte, die vom Hauptprogramm eingebunden werden, um weitere Fähigkeiten zum Programm hinzu zu fügen – sog. „Header-Dateien“ (Suffix: .hpp)
Makefiles (Dateien mit Compileranweisungen zur Übersetzung des Programms, kein Suffix)
Vom Programm zu speichernde oder zu lesende Datendateien (Suffix: frei wählbar)
Grafiken (Suffix: .png | .jpg | .ico, usw …)
Textdatei mit einer Beschreibung des Programmes und/oder einer TODO-Liste (Suffix: .txt)
Für unser erstes Projekt könnte das dann z. B. so aussehen:
Erstelle zunächst in deinem Sammelverzeichnis für Projekte den Unterordner 001_Hallo. Starte dann den Editor (Geany) und speichere das (noch leere) Programm unter dem Namen hallo.cpp in diesem Ordner ab. Gib danach den folgenden Quellcode (ohne Zeilennummern!) ein und achte darauf, alles so abzutippen, wie ich es hier notiert habe:
/*
C++ Einsteiger Tutorial
Source: hallo.cpp
*/
#include <iostream>
int main()
{
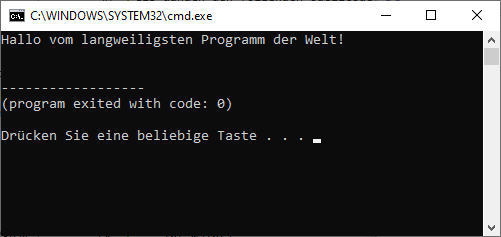
std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl;
return 0;
}
Drücke nun die Funktionstaste , um das Programm zu compilieren. Wenn du alles richtig gemacht hast, meldet der Compiler:
Falls jedoch Fehlermeldungen aufgetreten sein sollten, dann klicke auf die jeweilige Fehlermeldung im Meldungsfenster und vergleiche deine Eingaben mit dem Programmlisting. Korrigiere die aufgetretenen Fehler und compiliere das Programm erneut. Alte Hasen unter den Programmierern nennen diesen Vorgang eine Strafschleife…
Wenn keine Fehlermeldungen mehr auftauchen, dann ist es an der Zeit, unser erstes Programm zu testen. Drücke hierfür die Funktionstaste <F5> – es öffnet sich eine Kommandozeile:
Erwartungsgemäß gibt das Programm den Text „Hallo vom langweiligsten Programm der Welt!“ aus – und eine weitere, wichtige Information:
(program exited with code: 0)
Diese Meldung repräsentiert den Rückgabewert (später mehr dazu!) der Anwendung. Ein Kommandozeilen-Programm kann zu Diagnosezwecken beim Beenden unterschiedliche Codes an die Kommandozeile zurückgeben! Schließe nun die Kommandozeile durch Drücken einer beliebigen Taste.
hallo.cpp – Programmanalyse
Der Quellcode hallo.cpp mutet dir sicher noch sehr kryptisch an. Nehmen wir unser erstes Programm einmal genauer unter die Lupe und betrachten seine Bestandteile:
Zeile 1: Die Sequenz „/*“ leitet einen mehrzeiligen Kommentar ein, der in Zeile 4 mit der Sequenz „*/“ abgeschlossen wird. Alle, was zwischen diesen beiden Sequenzen steht, gilt als Kommentar und wird vom Compiler komplett ignoriert.
die Zeilen 2 und 3 enthalten einen kurzen, erklärenden Kommentar zum Programm.
Zeile 5 ist eine Leerzeile. Sie dient der Strukturierung des Programmcodes und damit der besseren Lesbarkeit.
Zeile 6: Die Angabe von #include veranlasst den Präprozessor (Bestandteil des Compilers) zum Einbinden einer Datei in den jeweiligen Quellcode. Die Präprozessor-Anweisung #include <iostream> bindet eine sogenannte System-Header-Datei – in diesem Fall enthält sie Definitionen und Funktionen der Ein-/Ausgabebibliothek für C++ und stellt u. a. den Ausgabestream cout für die Ausgabe von Texten in der Kommandozeile zur Verfügung. Im Gegensatz zu C besitzen System-Header-Dateien keinen Suffix. Sie werden innerhalb eines Paares spitzer Klammern aufgerufen, der Präprozessor sucht sie automatisch im Include-Verzeichnis des Compilers. Möchte man hingegen eigene Header-Dateien (Suffix per Konvention: .hpp oder .h) einbinden, so setzt man diese innerhalb eines Paares von Hochkommata (aka Anführungszeichen). Wird kein expliziter Pfad angegeben, so sucht der Präprozessor im aktuellen Verzeichnis:
Beispiel 1: #include "hallo_functions.hpp"
Beispiel 2: #include "D:\Projekte\my_functions.hpp"
Zeile 7: Funktionskopf der „Hauptfunktion“ main(), der Steuerung des Programmablaufs eines jeden C++-Programms. Funktionen bestehen grundsätzlich aus einem Funktionskopf mit Angabe der Datentypen für Rückgabewert und Funktionsparametern, dem Funktionsnamen, den in runde Klammern gefassten Funktionsparametern und einem zwischen geschweiften Klammern eingebetteten Funktionsrumpf, innerhalb dessen sich die Funktionslogik befindet – die genaue Verwendung des Begriffs „Datentyp“ klären wir noch. Die Funktion main() ist einzigartig im gesamten Quellcode und darf sich, im Gegensatz zu anderen Funktionen, nicht selbst aufrufen.
Zeile 8: Öffnende geschweifte Klammer des Funktionsrumpfes
Zeile 9: Anweisungen zur Ausgabe eines Textes und dessen Formatierung. Die Bestandteile im Einzelnen: std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl; Der Ausgabestream cout ist Bestandteil des Namensraums (aka namespace) std. Da wir es eingangs versäumt haben, dem Compiler diesen Namensraum mittels der Anweisung using namespace std; bekannt zu machen, müssen wir den Ausgabestream explizit unter Angabe seines Namensraums mit dem Präfix std:: aufrufen: std::cout. Das Präfix std::cout teilt dem Compiler mit, dass das Ausgabestream-Objekt cout im Namensraum der Standardbibliothek liegt.
Exkurs: Namensräume bieten eine Methode zur Vermeidung von Namenskonflikten in großen Projekten. Symbole, die innerhalb eines Namespace-Blocks deklariert sind, werden in einen benannten Bereich platziert, der verhindert, dass sie mit gleichnamigen Symbolen in anderen Bereichen verwechselt werden. Es sind mehrere Namespace-Blöcke mit demselben Namen zulässig. Alle Deklarationen innerhalb dieser Blöcke werden in dem benannten Bereich deklariert. Wir gehen später ausführlicher auf dieses Thema ein.
Der Verkettungsoperator << überträgt die auf ihn folgende Zeichenkette an das Ausgabestream-Objekt cout.
Die Zeichenkette (aka String) „Hallo vom langweiligsten Programm der Welt!“ folgt dem Verkettungsoperator und soll ausgegeben werden. Zeichenketten werden zwischen Hochkommata eingeschlossen und können Steuerzeichen enthalten – das ist in diesem Beispiel allerdings nicht der Fall.
Der auf die Zeichenkette folgende Verkettungsoperator bewirkt einen Zeilenvorschub durch Verknüpfung mit dem Manipulator endl.
Der Manipulator endl bewirkt einen Zeilenvorschub und leert den Ausgabestream. Hinweis: Würde man lediglich einen Zeilenvorschub erreichen wollen, so müsste man stattdessen das Steuerzeichen \n innerhalb der vorangegangenen Zeichenkette platzieren: ... << "Hallo vom langweiligsten Programm der Welt \n"
Das Semikolon schließt die zusammengesetzte Anweisung (aka „den Befehl“) ab und sorgt für die Ausführung. Unter C++ schließt man Anweisungen grundsätzlich mit einem Semikolon ab!
Zeile 10: Die Anweisung return 0; liefert den Wert Null an den Aufrufer (die Kommandozeile) zurück. Das Programm ist somit beendet.
Zeile 11: Schließende geschweifte Klammer des Funktionsrumpfes.
Das waren jetzt sehr viele Erklärungen und neue Begriffe auf einen Schlag! Lasse die Informationen ein Weilchen sacken und rekapituliere das Gelernte, bevor du mit dem nächsten Thema weitermachst.
Was geschieht beim Compilerlauf?
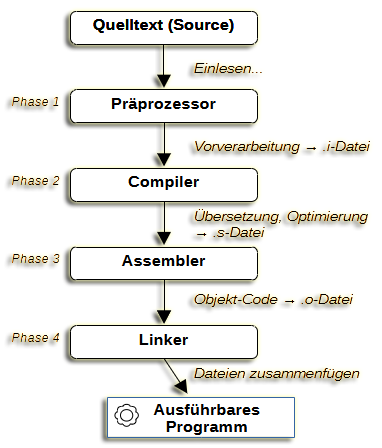
Die Kenntnis der genauen Abläufe während des Übersetzungsprozesses kann dir dabei helfen, Fehlermeldungen besser zu interpretieren und so einem Fehler schneller auf die Schliche zu kommen. Der Übersetzungsprozess erstreckt sich über vier Phasen – und in jeder Phase können spezifische Fehler auftreten.
Die vier Phasen des Übersetzungsprozesses:
Unser erstes lauffähiges Programm haben wir nun erstellt und seine Bestandteile besprochen. Gehen wir einen Schritt zurück und schauen uns den Prozess, den der Compiler durchläuft, wenn er dein Programm erstellt, einmal genauer an.
Das Verständnis dieser Abläufe ist deshalb wichtig, weil es verschiedene Arten von Fehlern gibt, die beim Schreiben von Code auftreten könnten. Es wird dir dabei helfen, eventuelle Fehler einzugrenzen und leichter aufzuspüren. Wenn ein Programm aus dem Quellcode erstellt wird, arbeiten vier Tools daran, bevor es sich um eine ausführbare Datei handelt: Der Präprozessor, der Compiler, der Assembler und der Linker.
Auch wenn es sich im Sprachjargon so eingebürgert hat, handelt es sich bei g++ genau genommen nicht wirklich um den Compiler, sondern viel mehr um eine Benutzer- schnittstelle, welche die Arbeit der einzelnen Compiler-Bestandteile koordiniert. Diese Schnittstelle leitet, in Abhängigkeit von übergebenen Parametern und im Quellcode hinterlegten Präprozessor-Anweisungen, die entsprechenden Phasen der Compilierung ein:
Phase 1: Der Präprozessor
Der Präprozessor nimmt den unverarbeiteten Quellcode als Eingabe entgegen und führt einige kleinere Bearbeitungen durch, bevor der von ihm erzeugte Code an den Compiler weitergeschickt wird. Er entfernt u.a. Kommentare und fügt den Inhalt von mit #include-Anweisungen eingebundenen Dateien in den von ihm erstellten Zwischencode ein. Es gibt weitere Präprozessor-Anweisungen, die wir zu einem späteren Zeitpunkt ausführlicher behandeln werden.
Phase 2: Der Compiler
Der Compiler übersetzt den C++-Code in Maschinensprache (Assembler). Assembler-Code ist viel, viel näher an den Anweisungen, die der Computer versteht dran und bleibt dabei für den Menschen lesbar. Der erzeugte Code ist spezifisch für den Prozessor, für den er geschrieben wird.
Phase 3: Der Assembler
Der Assembler erstellt aus dem vom Compiler erzeugten Assembler-Code Objektcode und legt diesen in Objektdateien, die eine .o-Erweiterung haben, ab. Objektcode besteht aus den tatsächlichen maschinenausführbaren Anweisungen, die vom Computer verwendet werden, um dein Programm auszuführen. Er ist jedoch noch nicht ganz ausführungsreif. Im gegenwärtigen Zustand gleichen die Objektdateien, aus denen Ihr Programm besteht, einer Reihe von Puzzlestücken, die erst noch zusammengesetzt werden müssen.
Phase 4: Der Linker
Der Linker fügt deine Objektdateien mit allen Bibliotheken, die du verwendest, zu einem ausführbaren Programm zusammen.
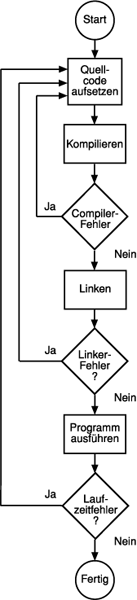
Der Entwicklungszyklus eines C++ Programms
Der vollständige Entwicklungszyklus eines C++ Programms umfasst noch mehr Aspekte, als bloß das Schreiben des Quelltextes und den Compilerlauf.
Am Anfang steht natürlich die Idee zum Programm und ihre Umsetzung in C++ – das Schreiben des Quelltextes.
Im zweiten Schritt wird der Quelltext durch einen Compilerlauf zu einem Object-Code übersetzt. Das kann auf Anhieb funktionieren – oder auch nicht.
Falls in diesem Stadium Compilerfehler auftreten, so muss deren Ursache im Quelltext gesucht und behoben werden. Diesen Vorgang nennt man Source Level Debugging. Anschließend erfolgt ein weiterer Compilerlauf.
Geht nun alles glatt, dann wird versucht, den erzeugte Object-Code durch den Linker um erforderliche Bibliotheken zu erweitert und zu einem ausführbaren Programm zu „binden“.
Falls der Linker Fehler meldet, so müssen die Ursachen erneut im Quelltext gesucht und ein neuer Compilerlauf angestoßen werden. Ist dieser dann erfolgreich, so wird das fertige Programm erzeugt und kann jetzt auf Laufzeitfehler getestet werden. Dazu startet man das Programm und vergleicht sein Verhalten und seine Ausgaben mit den bei Programmlegung festgelegten Erwartungen.
Laufzeitfehler führen zum Absturz des ausgeführten Programms, zu falschen Ergebnissen oder zu nicht vorhersehbarem Verhalten des Programms. Die Ursachen dafür können sehr unterschiedlich sein – beispielsweise wenn Variablen mit falschen/inkonsistenten Daten überschrieben oder gefüllt werden, die in nachfolgenden Befehlen zu Fehlern führen. Laufzeitfehler sind deutlich schwerer aufzuspüren, als einfache Syntaxfehler. In der Regel kommt dann ein Debugger zum Einsatz, mit dem man das Verhalten von Speicheradressen und Variableninhalten zur Laufzeit mitverfolgen kann. GCC stellt hierfür den gdb Debugger zur Verfügung.
Ein Programm ist erst dann als vollständig entwickelt anzusehen, wenn es fehlerfrei läuft.
Um mit C++ programmieren zu können, brauchst du eigentlich nur einen auf deinem Betriebssystem lauffähigen Compiler für C++ und einen entsprechenden Texteditor. Dein Texteditor sollte unbedingt visuelle Zeilennummerierung und die Syntax-Hervorhebung (aka Highlighting) für C++ unterstützen, das macht das Schreiben von Programmen und die Fehlersuche wesentlich einfacher.
Unter Linux bist du von vorn herein fein raus – das OS bringt die GNU Compiler Collection (GCC) und diverse Texteditoren mit oder ohne GUI bereits mit. Du brauchst die entsprechenden Pakete nur mit dem Paketmanager deiner Linux-Distribution zu installieren. Kostet keinen Cent.
Auch unter Windows stehen diverse Compiler-Systeme und Editoren zur Verfügung – neben wahren Monstern wie dem Microsoft Visual Studio u. a. auch die GNU Compiler Collection GCC. Empfehlenswerte Text-Editoren sind u.a. Geany, Notepad++ und die Entwicklungsumgebung Code::Blocks.
Auf einem Macunter OS X musst du zunächst erst XCode installieren. Die Entwicklungsumgebung bringt alle nötigen Bestandteile für die Programmierung mit C++ mit.
Betrachtungen zur Entwicklungsumgebung
Um Programme in C++ schreiben zu können, benötigst du also eine Entwicklungs- umgebung und die besteht in ihrer einfachsten Form aus zwei grundlegenden Komponenten: Einem Compilersystem für C++ und einem dedizierten Texteditor zur Erfassung der Quelltexte.
Beides kostenlos zu beschaffen ist heute kein Problem. Unter Linux steht alles, was du zum Programmieren benötigst, ohnehin im Paketmanager der jeweiligen Distribution zur Verfügung. Für andere Betriebssysteme existieren vorkonfigurierte Lösungen, wie z. B. Microsoft Visual Studio Community Edition unter Windows oder XCode auf dem Mac. Solche Komplettlösungen bieten neben vielen Vorteilen allerdings auch einige gravierende Nachteile für Einsteiger. Sie sind zunächst unübersichtlich, aufwendig zu konfigurieren, erfordern zusätzliche Einarbeitungszeit und lenken dich so erst mal von der eigentlichen Aufgabe ab: Programmieren lernen!
Für dieses Tutorial werden wir uns eine maßgeschneiderte eigene, zukunftssichere Entwicklungsumgebung für C++ zusammenstellen, die nicht nur den Bedürfnissen eines Einsteigers gerecht wird, sondern später auch das Programmieren von Anwendungen mit grafischer Benutzeroberfläche erlaubt.
1 – Der Compiler
Um einen Quelltext in ein lauffähiges Programm zu übersetzen, bedarf es eines C++-Compilers. Ich habe mich hier für die C/C++-Komponenten aus der GNU Compiler Collection (GCC – GNU gcc/g++) entschieden – diese sind stets aktuell, mächtig, erfüllen annähernd die neuesten Sprachstandards und stehen für alle gängigen Betriebssysteme zur Verfügung. Insgesamt unterstützt die GCC mehr als 60 Plattformen. Die Programme der GCC sind ein gut etablierter Standard für Programmierer und werden auch im professionellen Umfeld entsprechend gern und häufig eingesetzt.
GNU Compiler Collection herunterladen
GNU gcc/g++findet man in verschiedenen Varianten im Internet. Auch wenn es ein wenig Overhang bedeutet, werden wir in diesem Tutorial mit Hinblick auf die spätere Entwicklung von Programmen mit grafischer Benutzeroberfläche (nicht Bestandteil dieses Tutorials!) die Installation zusammen mit dem Qt Frameworkund dem Qt-Creator vornehmen.
Unter Linux installiere einfach alle Komponenten für Qt5, Qt6 und den Qt-Creator über den Paketmanager deiner Distribution. Für andere Betriebssysteme gilt:
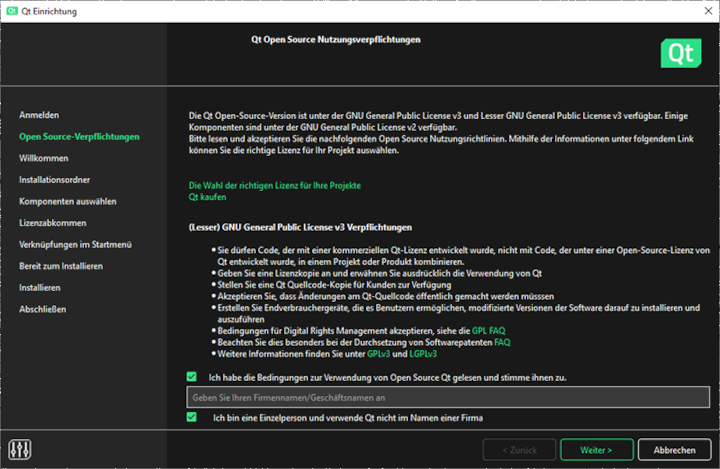
Melde dich im Installer mit deinen Zugangsdaten an und klicke auf <weiter>
Setze die Haken für die Checkboxen wie im folgenden Bild: Klicke auf <weiter>
Durchlaufe mit die Installationsroutine bis zum Punkt „Benutzerdefinierte Installation“. Bestimme den Speicherort für die Installation von Qt und klicke auf <weiter>
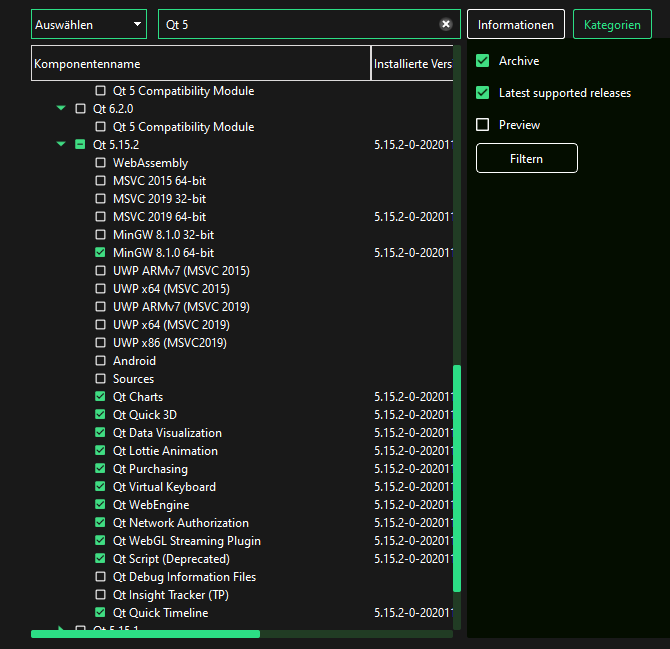
Setze die Haken bei „Qt Creator“, „Additional Libraries“ und in der aktuellsten Qt6 Release Version den Haken bei „MinGW 11.2.0 64-bit“.
Gib im Suchfeld „Qt 5“ ein. Unter dem Eintrag „Qt 5.15.2“ selektiere mindestens den Eintrag „MinGW 8.1.0 64-bit“ und die Einträge für die zusätzlichen Bibliotheken:
Unter „Developer and Designer Tools“ selektiere die Einträge „Qt Creator“, „MinGW 13.0.1 64-bit“, „MinGW 11.1.0 64-bit“, „MinGW 8.1.0 64-bit“, „CMake“ und „Ninja“.
Zum Start der Installation klicke auf und fasse dich in Geduld…
Einrichtung des Compilers
Um den Compiler von der Kommandozeile aus erreichen zu können ist es notwendig, die PATH Variable deines Betriebssystems entsprechend um den Pfad zum Compiler zu erweitern. Unter Linux geschieht das automatisch bei der Installation von gcc, unter anderen Betriebssystemen musst du die Anpassung selbst vornehmen.
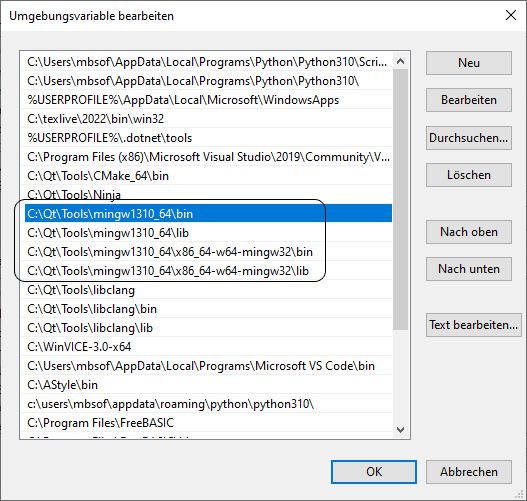
Angenommen, du befindest dich unter Windows, bist der Installationsanleitung gefolgt und hast Qt nach C:\Qt installiert. Die aktuell höchste installierte Version von MinGW (gcc) findest Du dann unter C:\Qt\Tools\mingw1310_64.
Öffne den Dialog zur Einstellung von Umgebungsvariablen, selektiere „PATH“ und erweitere die Variable um die aus dem folgenden Bild ersichtlichen Einträge:
Bestätige den Dialog und alle übergeordneten Instanzen, öffne eine neue Kommandozeile und teste deine Einstellungen durch Eingabe von gcc -v:
Dein Compiler-System sollte nun einsatzbereit sein. Für das Setzen von Systemvariablen unter anderen Betriebssystemen konsultiere bitte das entsprechende Handbuch.
Verwenden des Compilers
Am Einfachsten ist es, den Compiler über entsprechende Befehle aus dem Editor heraus zu steuern – und das ist auch die bevorzugt Vorgehensweise in diesem Tutorial. Trotzdem kann es nicht schaden, wenn du weißt, wie man den Compiler auch auf der Kommandozeile bedienen kann.
Für die Übersetzung von C++-Quelltexten verwenden wir GNU g++, das C++-Compiler Backend der GNU Compiler Collection. Es wird über diverse Schalter gesteuert, die sein Verhalten regeln. Hier eine kurze Aufstellung der wichtigsten Schalter:
-Wall (Warn all) sorgt dafür, dass der Compiler neben Fehlern auch auf sämtliche Warnungen bei der Übersetzung eines Programmes reagiert und diese ausgibt
-v (verbose) bewirkt eine sehr detaillierte Ausgabe von Compilermeldungen
-std= <Bezeichner> bewirkt die Verwendung eines bestimmten, definierten Compilerstandards
-s (strip) bewirkt die Optimierung der Größe des erzeugten Programms
-g, -ggdb (gnudebug) fügt dem erzeugten Programm sogenannten Debug-Code hinzu – das Programm lässt sich so mit dem Debugger (Werkzeug zur Fehlersuche) gdb aus der GNU Compiler Collection auf Fehler überprüfen
-o (output) speichert das übersetzte Programm unter einem frei wählbaren Namen
-l (Library) bindet eine zusätzliche Linker-Bibliothek ein. Häufig verwendet wird z. B. -lm zur Einbindung der mathematischen Bibliothek für arrithmetische CoProzessoren (FPU)
-O (optimize) bewirkt die Optimierung des zu übersetzenden Programms, wobei der Parameter für die Optimierungsstufe steht. Üblich ist z.B. -O3. Optimierungen sollten nur bei einem vorher ausgiebig getesteten, für die Veröffentlichung bestimmten Programm zugeschaltet werden!
Zum Compilieren eines Programms auf der Kommandozeile musst du dich in dem Verzeichnis befinden, in dem der zugehörige Quelltext gespeichert ist. Der übliche Aufruf von g++ für die Programme in diesem Tutorial lautet dann: g++ -Wall -std=c++17 -o meinProgramm meinCode.cpp
Dabei gibt g++ sämtliche auftretenden Fehlermeldungen und Warnungen unter Verwendung des ISO/ANSI-Standards c++17 auf der Kommandozeile aus und erstellt aus dem Quelltext meinCode.cpp das lauffähige Programm meinProgramm. Unter DOS/Windows wird automatisch noch der Suffix .exe an den Programmnamen angehängt. Das fertig übersetzte Programm befindet sich danach im gleichen Verzeichnis wie der zugehörige Quellcode und kann durch
meinProgramm + <Eingabetaste>
zur Ausführung gebracht werden.
Der Compiler besitzt noch viele weitere Schalter und Optionen. Außerdem enthält die GNU Compiler Collection weitere nützliche Tools und Hilfsprogramme. Eine vollständige Beschreibung findest Du in den Handbüchern unter https://gcc.gnu.org/onlinedocs/gcc-13.3.0/gcc/
2 – Der Editor
Zum Schreiben von Programmen brauchst Du, wie bereits gesagt einen Editor, der deine Quelltexte als einfache ASCII-Dateien speichern kann. Grundsätzlich könnte man hierfür nun den Qt-Creator oder andere Speichermonster wie Visual Studio Code, Word oder LibreOffice Writer mit speziellen Speicheroptionen einsetzen – jedoch ist es deutlich angenehmer, auf einen Editor zurück zu greifen, der dich nicht ablenkt, Nützlichkeiten wie Syntax Highlighting, Code Folding und Auto-Vervollständigung beherrscht und am Besten auch gleich noch den Compiler anzusprechen vermag. Die Puristen unter den Programmierern nehmen hierfür GNU Emacs, vi oder nano unter Linux, wir allerdings wollen es in diesem Tutorial etwas bequemer haben.
Es existiert eine mehr oder minder reiche Auswahl an solchen Editoren für die verschiedenen Betriebssysteme. In diesem Buch gehe ich davon aus, dass du den quelloffenen Editor „Geany“ verwendest – er erfüllt alle oben genannten Kriterien und ist für Linux, Windows und MacOS kostenlos erhältlich.
Geany herunterladen und installieren
Unter Linux ist der Editor bereits Bestandteil vieler Distributionen – installiere das Programm einfach über den Paketmanager der von dir verwendeten Linux-Distribution. Für andere gebräuchliche Betriebssysteme gilt: Geany und seine Zusatzkomponenten kannst du hier für dein Betriebssystem herunterladen: https://www.geany.org/download/releases/ Um Geany zu installieren genügt es, den jeweiligen Installer für das von dir verwendete Betriebssystem zu starten.
Geany konfigurieren
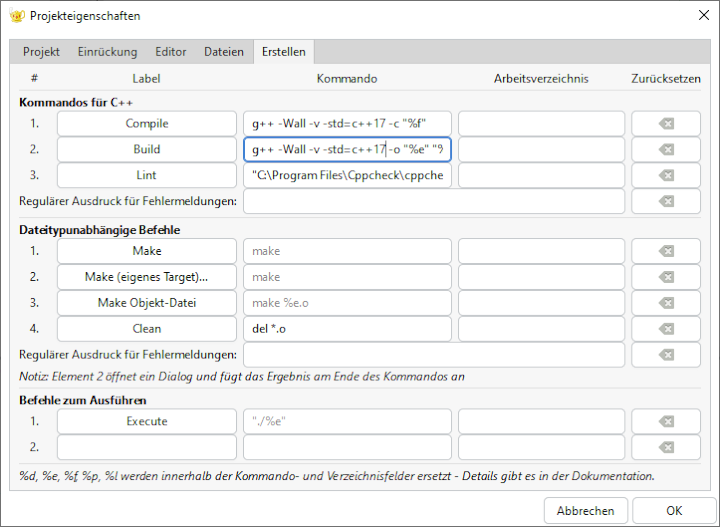
Geany kommt bereits vorkonfiguriert daher, unterstützt viele gängige Programmier- sprachen und erkennt selbstständig, mit Welcher du gerade arbeitest. Dabei lässt sich der jeweilige Befehlssatz zur Ansteuerung des Compilers aber noch nachjustieren. Klicke dazu im Menü „Erstellen“ auf den Eintrag „Kommandos zum Erstellen konfigurieren“ – es erscheint der folgende Dialog:
Die Compiler gcc und g++ übersetzen Programme standardmäßig mit gnu99, einer älteren Vorgabe für C/C++ mit einigen zusätzlichen Besonderheiten der GNU Compiler Collection. In diesem Buch wollen wir aber mit einem fortgeschrittenen, relativ aktuellen Sprachstandard arbeiten, wie er in den Normen c++14 und c++17 für ISO/ANSI C++ definiert ist.
Der Schalter -std veranlasst gcc/g++ dazu, einen anderen als den vorgegebenen Sprachstandard zu verwenden. Trage deshalb im Konfigurationsdialog hinter allen Vorkommen von g++ -Wall den Schalter -std=c++17 ein.
Der Schalter -Wall (Warn all) sorgt dafür, dass der Compiler Warnungen und Fehlermeldungen ausgibt. Das ist besonders nützlich für die Fehlersuche im Quelltext. Besonders geschwätzig wird der Compiler, wenn du zusätzlich noch den Schalter -v (verbose) einfügst – allerdings wird die Ausgabe der Meldungen dann schnell unübersichtlich.
Geany verwenden
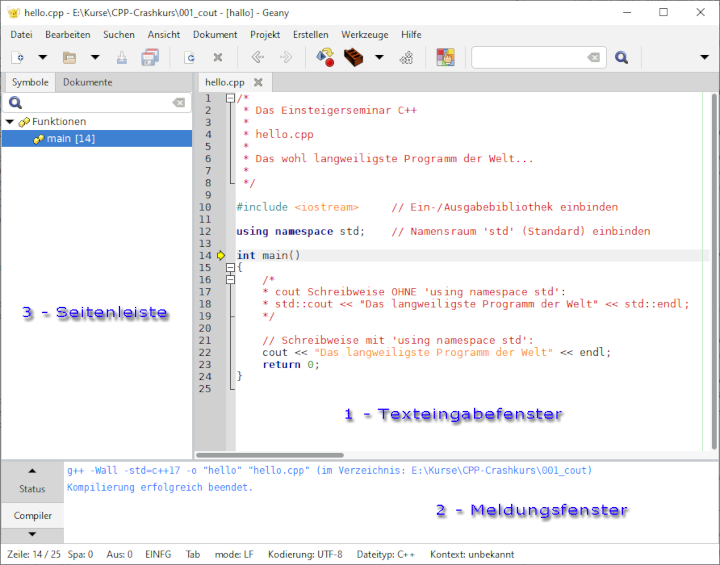
Geany zeichnet sich durch Schlichtheit und Funktionalität aus – alles ist intuitiv und leicht erreichbar. Das folgende Bild illustriert den Aufbau des Editors:
Texteingabefenster: Hier gibst du deine Programme ein.
Meldungsfenster: Hier erfolgt die Ausgabe von Compilermeldungen. Falls bei der Übersetzung ein Fehler oder eine Warnung aufgetreten ist, so kannst du diese anklicken – die Schreibmarke springt dann im Texteingabefenster auf die vermutete Stelle, an der ein Problem aufgetreten ist.
Seitenleiste: Hier listet der Editor Klassen, Funktionen, Strukturen und andere Elemente von C++ auf. Durch einen Klick auf einen Eintrag springt die Schreibmarke zur entsprechenden Stelle im Texteingabefenster.
Die Arbeit mit dem Editor gestaltet sich denkbar einfach:
Programme schreiben: Gib deinen Quelltext im Texteingabefenster ein und speichere ihn unter einem aussagekräftigen Namen mit der Dateiendung .cpp ab.
Übersetzung anstoßen: Drücke die Funktionstaste <F9> , um den Quelltext compilieren zu lassen. Veränderungen am Quelltext werden dabei automatisch gespeichert. Falls du den Quelltext noch nicht abgespeichert hast, so musst du das vor dem ersten Compilerlauf nachholen.
Programm ausführen: Drücke die Funktionstaste <F5>, um das fertige Programm zu starten.
Die Programmiersprache C++ ist weltweit eine der beliebtesten Entwicklersprachen für professionelle Software. Mit ihr kannst du sehr systemnah komplexe und schnelle Programme schreiben, die mit wenig Aufwand auf nahezu jedes beliebige Betriebssystem portierbar sind, für das es einen C++-Compiler gibt.
C++ wurde ab 1979 von Bjarne Stroustrup bei AT&T als Erweiterung der Programmiersprache C entwickelt. Die Sprache ermöglicht sowohl die effiziente und maschinennahe Programmierung als auch eine Programmierung auf hohem Abstraktionsniveau. Was Stroustrup hinzufügte, sind die Merkmale der objektorientierten Programmierung (OOP). Somit wird – zumindest theoretisch – das bis dahin gängige Paradigma der prozeduralen Programmierung zugunsten eines dem menschlichen Denken ähnlicheren Ansatzes abgelöst.
C++ wie auch C sind Compilersprachen – was besagt, dass der Quellcode vor der Ausführung in Maschinensprache übersetzt werden muss. Diese Aufgabe kommt dem C++-Compiler zu. C++ ist eine Obermenge von C – das besagt, dass jedes gültige C-Programm mit einem C++-Compiler übersetzt werden kann. Was es keinesfalls besagt ist, dass du über C-Kenntnisse verfügen musst, um C++ zu erlernen! Die beiden Sprachen sind nicht annähernd so nah miteinander verwandt, wie man auf den ersten Blick glauben möchte und oft ist es besser, ohne festgefahrene Strukturen an eine neue Sprache heran zu gehen.
Die Sprache C++ verwendet nur etwa 60 Schlüsselwörter („Sprachkern“), manche werden in verschiedenen Kontexten (static, default) mehrfach verwendet. Ihre eigentliche Funktionalität erhält sie, ähnlich wie auch die Sprache C, durch die C++-Standardbibliothek, die der Sprache fehlende wichtige Funktionalitäten beibringt (Arrays, Vektoren, Listen, . . . ) wie auch die Verbindung zum Betriebssystem herstellt (iostream, fopen, exit, . . . ). Je nach Einsatzgebiet kommen weitere Bibliotheken und Frameworks dazu. C++ legt einen Schwerpunkt auf die Sprachmittel zur Entwicklung von wiederverwendbaren Bibliotheken. Dadurch favorisiert es verallgemeinerte Mechanismen für typische Problemstellungen und besitzt nur wenige, kaum in die Sprache integrierte Einzellösungen.
BASIC ist ja die Sprache, mit der die Meisten meines Jahrgangs ihre ersten Schritt als Programmierer gemacht haben. Bei mir waren das Commodore BASIC 2.0 auf dem legendären C64, Commodore BASIC 3.5 auf dem C16/Plus4, AmigaBasic, GFA-Basic und MaxonBASIC auf dem Amiga – und natürlich GW-BASIC und Microsoft QuickBasic auf der ersten MS-DOS-Kiste in meiner Raupensammlung. Nach wie vor ist BASIC eine Programmiersprache, die viele Vorteile bietet: Sie ist leicht zu erlernen, je nach BASIC-Dialekt auch für mächtige Programmimplementierungen gut zu gebrauchen – und BASIC macht Spaß.
Auch heute noch verwende ich gerne mal BASIC für schnelle Entwürfe und Machbarkeitsstudien (PureBASIC), aber auch für komplexere Programme, wenn ich nicht auf C++ und Qt6 zurückgreifen möchte. Oft liefern mir dabei alte BASIC-Listings die Ideen für die Umsetzung von Programmen – und hier kommt QB64 ins Spiel…
Was ist QB64?
QB64 (ursprünglich QB32) ist ein BASIC-Compiler für Windows, Linux und Mac OS X, der für die Kompatibilität mit Microsoft QBasic und QuickBASIC entwickelt wurde. QB64 emittiert C-Quellcode und integriert selbst einen C++-Compiler, um die letztendliche Kompilierung des generierten Zwischencodes mit gcc-Optimierung zu ermöglichen. Mit der derzeit technisch genauesten Nachbildung des originalen Microsoft-Produkts zählt QB64 zu den Anwendungen im Bereich Retrocomputing.
QB64 implementiert die meisten QBasic-Funktionen und kann viele QBasic-Programme ausführen, einschließlich der Beispielprogramme Gorillas und Nibbles, die von Microsoft geschrieben und dem Originalprodukt beigelegt waren. Darüber hinaus enthält QB64 eine Entwicklungsumgebung, die der QBasic-Entwicklungsumgebung ähnelt. QB64 erweitert auch die QBASIC-Programmiersprache um 64-Bit-Datentypen, bessere Sound- und Grafikunterstützung und bessere Anbindung an Betriebssystemfunktionen. Es kann auch einige DOS/x86-spezifische Funktionen wie Mauszugriff über den Interrupt 33h und mehrere Timer emulieren.
QB64 unter Linux
Meistens arbeite ich an einem Linux-Rechner und was liegt da näher, als QB64 auch hier zu verwenden? Das Programm ist kostenlos, OpenSource – und es lässt sich klaglos sowohl auf den 64-Bit-, als auch auf den 32-Bit-Versionen der gängigen Linux-Distributionen kompilieren. In diesem Tutorial zeige ich dir, wie man QB64 unter Debian 12 Linux (aka „Bookworm“) installiert.
Quellcode besorgen und QB64 compilieren
QB64 existiert derzeit in zwei Versionen. Während die ursprüngliche Originalversion nur noch sporadisch aktualisiert wird (Version 2.02), gibt es auch noch einen wesentlich aktuelleren Branch, die „Phoenix Edition“mit einem erweiterten Befehlssatz, die (Stand 03/2025) noch aktiv weiterentwickelt wird. Beide haben ihre Vor- und Nachteile. Die ursprüngliche Version zeichnet sich durch schnellere Compilerzeiten mit vergleichsweise langsamem Programmcode aus, während die Phoenix Edition den Quellcode deutlich langsamer übersetzt, dafür aber hochoptimierte, schnelle Programme erzeugt. Es bleibt dir selbst überlassen, welcher Version du den Vorzug gibst.
Um darauf zugreifen zu können, musst du auf deiner Linux-Maschine zunächst ein paar Vorbereitungen treffen:
# 1. git installieren:
sudo apt install git
# 2. Verzeichnis für Quellcodes einrichten:
mkdir ~/git
# 3. Verzeichnis betreten:
cd ~/git
# 4. QB64 Quellcode abrufen:
# Original-Version:
git clone https://github.com/QB64Team/qb64.git
# oder Phoenix Edition:
git clone https://github.com/QB64-Phoenix-Edition/QB64pe.git
# Hinweis: Wenn du dich für die Phoenix Edition entscheidest, dann solltest
# du zusätzlich das Paket kdialog installieren - andernfalls musst du beim
# Laden und Speichern von Quellcode Pfad und Programmname umständlich in
# einer Shell eingeben!
sudo apt install kdialog
Das Herunterladen kann ein Weilchen dauern. Sobald der Download beendet ist, kannst du QB 64 compilieren. Eventuell fehlende Pakete und Abhängigkeiten werden dabei automatisch nachinstalliert. Die weitere Vorgehensweise bleibt für beide Versionen die Gleiche:
# 5. Wechsle in das qb64-Verzeichnis:
# Original-Version:
cd qb64
# oder Phoenix Edition:
cd QB64pe
# 6. Starte die Übersetzung:
./setup_lnx.sh
# 7. Warteschleife... Programm wird übersetzt.
# Koch dir ein Käffchen oder wende dich deinem Haustier zu...
Sobald der Compiler fertig ist, öffnet sich die Entwicklungsumgebung von QB64. Das Installations-Script hat übrigens automatisch eine Verknüpfung in deiner Startleiste angelegt! Du findest QB64 künftig unter Entwicklung->QB64 Programming IDE und kannst somit jederzeit mit dem Programmieren in BASIC loslegen. 😉
Programmieren mit QB64/QBasic – Links zu Tutorials und Foren
Vielleicht hast du ja Lust auf Retro-Programming mit BASIC und QB64 bekommen? Hier habe ich einige hilfreiche Links zusammengetragen, die dir beim Einstieg und der täglichen Arbeit nützlich sein können:
Programmieren in QBasic ein weiterer guter Einsteiger-Kurs, der sich vor allem an Schüler wendet.
QBasic-Kurs für Gymnasien Kleiner Qbasic-Einsteigerkurs auf 13 Seiten. Hierbei handelt es sich um eine Zusammenfassung eines 8-stündigen QBasic-Programmierkurses am Gymnasium Wolbeck.
„Basic lernen“ – 8-teiliges Online-Tutorial Exzellentes QBasic-Tutorial, das systematisch in die wichtigsten Funktionen und Befehle von QBasic einführt. Liebevoll aufbereitet, mit vielen Programmbeispielen. Auch für absolute Neueinsteiger ideal geeignet.
Modernes QuickBasic ein Tutorial für Fortgeschrittene und Profis in der QB- Programmierung Dieser Kurs füllt eine Lücke – ein Tutorial, das viele Fragen von fortgeschrittenen Programmierern beantwortet und diesen wertvolle Tipps gibt. Der bunte Themenreigen spannt sich von der Interrupt- Programmierung über das modulare Programmieren mit MAKE-Modulen und INCLUDE-Dateien bis hin zur Programmierung einer eigenen Scriptsprachen- Interpreters mit QB.
Die QB Monster FAQ In dieser FAQ (Frequently Asked Questions) sind all die Fragen gesammelt und beantwortet, die seit Jahren hundertfach in allen QBasic-Foren weltweit gestellt werden. Die FAQ umfasst 1028 Fragen mit über 2000 Antworten.
Eine Anleitung zur Installation und Nutzung unter Debian-basierten Linux-Distributionen (32- und 64-Bit)
Lightscribe ist eine von HP und Lite-On im Jahr 2006 entwickelte Technik zum Beschriften einer CD oder einer DVD mit Hilfe eines CD/DVD-Brenners. Für eine solche Beschriftung sind spezielle Rohlinge und LightScribe-fähige Brenner nötig.
Seit ca. 2013 wurde LightScribe obsolet, obwohl das System auch nach heutigem Stand durchaus eine brauchbare Methode zur Beschriftung von optischen Datenträgern darstellt. Bereits im Laufe des Jahres 2011 stellte HP den Einbau von LightScribe-fähigen optischen Laufwerken in HP-Notebooks und -Desktops ein. Auch andere Hersteller haben die Produktion von LightScribe-fähigen Laufwerken mittlerweile beendet. Die offizielle LightScribe-Website war noch bis 2013 erreichbar, ist aber zwischenzeitlich von HP entfernt worden, sodass LightScribe-Treiber und -Programme nur noch über inoffizielle Quellen bezogen werden können.
In der Folge wurden LightScribe-fähige Medien schnell ziemlich teuer und sind heute gefragte Verbrauchsmaterialien für Liebhaber und Nerds. Ich bin so Einer.
Wie arbeite ich mit diesem Tutorial?
Am besten liest du dir das komplette Tutorial einmal von vorne nach hinten durch und machst dir Stichpunkte – viele Aspekte zur Nutzung von LightScribe werden bereits im Abschnitt zur Installation auf 32-Bit Systemen angesprochen.
Benötigte Software
Um LightScribe unter Linux verwenden zu können, benötigst du die folgenden Packages:
lightscribe-1.18.27.10-linux-2.6-intel.deb (Treiber und System-Software)
gleiche Maschine, Windows Subsystem für Linux (WSL2)
Brenner: Externes HP LightScribe DVD-Drive, USB 2.0/USB 3.0
Vorbereitungen
Öffne eine Shell und aktualisiere zuerst dein Betriebssystem:
sudo apt update && sudo apt upgrade -y
Transferiere danach die benötigten Packages auf dein Zielsystem. Öffne eine Shell in dem Verzeichnis, in welchem du die Packages abgelegt hast. Wenn du das hier im Blog bereitgestellte Sammelarchiv verwendest, dann teste es zunächst auf eventuelle Fehler: unzip -t lightScribeLinux.zip
Entpacke anschließend das Archiv:
unzip -o lightScribeLinux.zip
Im Anschluss findest du ein neues Verzeichnis lightScribeLinux. Wechsle in dieses Verzeichnis und lasse es dir anschließend anzeigen:
cd lightScribeLinux ls -l
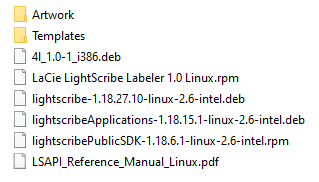
Du findest die folgenden Ordner und Dateien:
Bei den beiden Ordnern Artwork und Templates handelt es sich um zusätzliche Bilder und Templates für den LightScribe Labeler. Wir werden sie später an einen adäquaten Platz im Dateisystem verschieben. Die Datei LSAPI_Reference_Manual_Linux.pdf ist das Programmierer-Handbuch zu LightScribe – kopiere es in deinen Dokumente-Ordner, falls Du planst, eigene LightScribe-Anwendungen zu entwickeln.
Alle anderen Dateien sind Packages für die Debian (.deb) und RedHat (.rpm) Paketmanager. Sie werden für die Installation von LightScribe auf den unterschiedlichen Systemen benötigt.
Wichtig:
Bevor die Basis-Installation erfolgt, muss zuerst eine Gruppe wheel angelegt und die Benutzer, die später in der Lage sein sollen, CDs zu bedrucken, hinzugefügt werden. Ansonsten ist die Nutzung der im weiteren Verlauf genannten Programme nicht möglich!
BENUTZERNAME ist dabei durch den eigenen Benutzernamen zu ersetzen.
Installation auf 32-Bit Systemen (x32/i686)
Auf einem 32-Bit System verläuft die Installation von LightScribe nebst Anwender-Software relativ unspektakulär. Installiere zunächst das Basis-Paket mit dem Treiber und den Bibliotheken:
Es schadet nicht, anschließend für die sichere Verfügbarkeit der installierten Komponenten zu sorgen:
sudo apt install -f sudo ldconfig
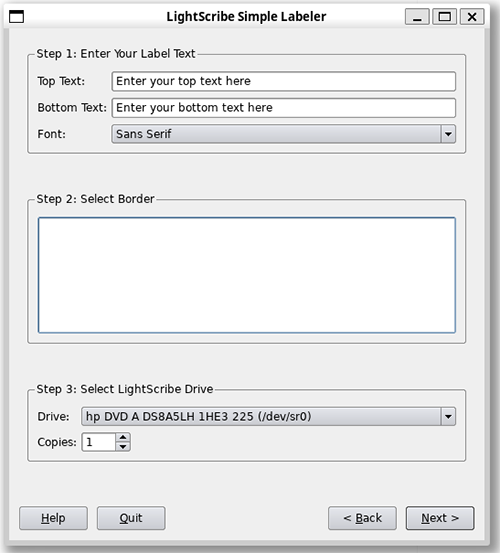
Nachdem wir nun Grundsystem und Anwendersoftware erfolgreich installiert haben, wird es Zeit für einen ersten Test. Rufe dazu den LaCie LightScribe Labelerin der Shell auf:
4L-gui
Das GUI ist intuitiv und weitgehend selbsterklärend. Templates können in den Formaten *.jpg, *.png, *.bmp und *gif mit einer Größe von 1200×1200 Pixeln als Graustufen-Bilder verarbeitet werden. Das Erstellen eigener Labels ist denkbar einfach. LightScribe Labeler sucht im Home-Verzeichnis des Users nach Vorlagen.
Das Sammelarchiv enthält den Ordner Artwork mit einigen hübsche Vorlagen. Kopiere sie in deinen Home-Ordner:
cp -R Artwork ~/username
Bei der Installation des Package lightscribeApplications-1.18.15.1-linux-2.6-intel.deb wurde unter /opt das Verzeichnis lightscribeApplications mit den Unterverzeichnissen common und SimpleLabeler erstellt. In common befinden sich die Qt4-Laufzeitkomponenten der Anwendung, im Verzeichnis SimpleLabeler findest du die Anwendung SimpleLabeler, ein einfaches Programm, mit dem du LightScribe-Rohlinge mit Text beschriften kannst. Testen wir auch dieses:
cd /opt/lightscribeApplications/SimpleLabeler sudo ./SimpleLabeler
Aha! Das funktioniert so nicht! Du erhältst die Fehlermeldung:
./SimpleLabeler: error while loading shared libraries: libpng12.so.0: cannot open shared object file: No such file or directory
Offenbar fehlt uns eine Systembibliothek? Nö, dem ist nicht so! Allerdings liegt die libpng unter Debian 12 in der Version 1.6 – und nicht, wie gefordert, in der Version 1.2 vor. Abhilfe schafft ein symbolischer Link:
cd /usr/lib/i386-linux-gnu ln -s libpng16.so libpng12.so.0 cd /opt/lightscribeApplications/SimpleLabeler sudo ./SimpleLabeler
Löppt! Zwar beschwert sich Linux mit der Warnung
libpng warning: Application built with libpng-1.2.5 but running with 1.6.39
aber das können wir getrost vernachlässigen.
Um SimpleLabeler ohne Umstände aus jedem Verzeichnis in einer Shell starten zu können, ändert man zunächst den Benutzer für den Pfad /opt/lightscribeApplications und fügt dann noch ein paar Zeilen zur Datei .bashrc im Home-Verzeichnis des jeweiligen Benutzers ein:
Melde dich anschließend in der Shell ab und starte sie neu oder gib direkt den folgenden Befehl ein:
source ~/.bashrc
Du kannst nun den LightScribe SimpleLabeler in der Shell direkt oder über seinen Alias starten:
# Direkt:
sudo SimpleLabeler
# via Alias:
slabeler
Um die Qualität des Kontrastes der Labels für die LightScribe-Programme zu beeinflussen, musst du das folgende Script ausführen:
sudo /usr/lib/lightscribe/elcu.sh
Du wirst nun nach einem Wert für den erweiterten Kontrast gefragt:
1 – schaltet den verstärkten Kontrast ein, die Dauer des Brennvorgangs erhöht sich drastisch.
2 – schaltet den verstärkten Kontrast ab, kürzerer Brenndauer
Hinweis:Um den Kontrastwert wieder zu verändern, rufst du das Script einfach erneut auf.
Somit können wir nun CD- und DVD-Labels brennen und hätten die Installation von LightScribe für den Durchschnittsanwender auf einer x32/i686-Architektur eigentlich schon gemeistert. Spannend wir es noch einmal, wenn auch das LightScribe SDK für Programmierer installiert werden soll – dieses liegt uns nämlich nur als RedHat-Paket vor und muss vor der Verwendung auf einem Debian-System erst umgewandelt werden. Hierzu installieren wir zunächst das Paket alien:
sudo apt install alien -y
Installation des LightScribe SDK
# Im ersten Schritt konvertieren wir das LightScribe SDK von
# RedHat-Paket-Format in das Debian-Paket-Format:
sudo alien lightscribePublicSDK-1.18.6.1-linux-2.6-intel.rpm
# Im zweiten Schritt installieren wir das soeben erstellte Paket:
sudo dpkg -i lightscribepublicsdk_1.18.6.1-1_amd64.deb
#...und zack! Es hagelt Fehlermeldungen:
Entpacken von lightscribepublicsdk (1.18.6.1-1) ...
lightscribepublicsdk (1.18.6.1-1) wird eingerichtet ...
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/docs/LSAPI_Reference_Manual.pdf' nicht möglich: Datei oder Verzeichnis nicht gefunden
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/linux_public_SDK_license.rtf' nicht möglich: Datei oder Verzeichnis nicht gefunden
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/sample/lsprint/lsprint.cpp' nicht möglich: Datei oder Verzeichnis nicht gefunden
dpkg: Fehler beim Bearbeiten des Paketes lightscribepublicsdk (--install):
»installiertes post-installation-Skript des Paketes lightscribepublicsdk«-Unterprozess gab den Fehlerwert 1 zurück
Fehler traten auf beim Bearbeiten von: lightscribepublicsdk
Was also tun? Das Problem besteht darin, dass verschiedene Dateien nicht entpackt werden konnten – sie liegen aber als gzip-Archive in den angegebenen Verzeichnissen! Die Lösung mutet etwas umständlich an, funktioniert aber hervorragend:
# 1. Fehler 1 beseitigen:
cd /usr/share/doc/lightscribe-sdk/docs/
sudo gzip -d LSAPI_Reference_Manual.pdf.gz
# 2. Fehler 2 beseitigen:
cd /usr/share/doc/lightscribe-sdk/
sudo gzip -d linux_public_SDK_license.rtf.gz
# 3. Fehler 3 beseitigen:
cd /usr/share/doc/lightscribe-sdk/sample/lsprint/
sudo gzip -d lsprint.cpp.gz
# 4. Fehlerhafte Installation in der Installationsdatenbank bereinigen:
sudo apt install -f
Installation auf 64-Bit Systemen (x64/amd64)
Die Packages für LightScribe entstammen noch aus einer Zeit, in der 32-Bit Systeme die Regel waren und funktionieren dementsprechend auch nur mit einer 32-Bit Architektur. Unter Debian 12 64-Bit musst du also zunächst eine zusätzliche 32-Bit Umgebung (multi-arch) installieren:
# Im ersten Schritt konvertieren wir das LightScribe SDK von
# RedHat-Paket-Format in das Debian-Paket-Format:
sudo alien --target=amd64 lightscribePublicSDK-1.18.6.1-linux-2.6-intel.rpm
# Im zweiten Schritt installieren wir das soeben erstellte Paket:
sudo dpkg -i --force-architecture lightscribepublicsdk_1.18.6.1-1_amd64.deb
#...und ding-dong! Wieder hagelt Fehlermeldungen:
Entpacken von lightscribepublicsdk (1.18.6.1-1) ...
lightscribepublicsdk (1.18.6.1-1) wird eingerichtet ...
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/docs/LSAPI_Reference_Manual.pdf' nicht möglich: Datei oder Verzeichnis nicht gefunden
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/linux_public_SDK_license.rtf' nicht möglich: Datei oder Verzeichnis nicht gefunden
chown: Zugriff auf '/usr/share/doc/lightscribe-sdk/sample/lsprint/lsprint.cpp' nicht möglich: Datei oder Verzeichnis nicht gefunden
dpkg: Fehler beim Bearbeiten des Paketes lightscribepublicsdk (--install):
»installiertes post-installation-Skript des Paketes lightscribepublicsdk«-Unterprozess gab den Fehlerwert 1 zurück
Fehler traten auf beim Bearbeiten von: lightscribepublicsdk
Die Lösung kennst du bereits aus dem Abschnitt zur Installation auf 32-Bit Systemen:
# 1. Fehler 1 beseitigen:
cd /usr/share/doc/lightscribe-sdk/docs/
sudo gzip -d LSAPI_Reference_Manual.pdf.gz
# 2. Fehler 2 beseitigen:
cd /usr/share/doc/lightscribe-sdk/
sudo gzip -d linux_public_SDK_license.rtf.gz
# 3. Fehler 3 beseitigen:
cd /usr/share/doc/lightscribe-sdk/sample/lsprint/
sudo gzip -d lsprint.cpp.gz
# 4. Fehlerhafte Installation in der Installationsdatenbank bereinigen:
sudo apt install -f
64-Bit Troubleshooting
Auf 64-Bit Systemen kann es schon mal vorkommen, dass du über diesen Fehler stolperst:
error while loading shared libraries: liblightscribe.so.1: cannot open shared object file: No such file or directory
Die Lösung für dieses Problem besteht darin, die Dateien liblightscribe.so und liblightscribe.so.1 von /usr/lib nach /usr/lib32 zu kopieren. Eben drum haben wir diesen Schritt gleich bei der Installation des Basis-Systems bereits durchgeführt!
So, das war’s dann soweit. Ich hoffe, du konntest etwas mit meinem Tutorial anfangen und hattest Spaß!
Findest du diesen Artikel hilfreich? Dann freue ich mich über einen kleinen Obolus für meine Rohling-Kasse. Besten Dank! 🙂
Auffällig bei den öffentlichen Reaktionen: Politiker fast aller Parteien – sogar die wiederbraune CDU – brachten ihr Entsetzen zum Ausdruck. Nicht so die blaue Nazipartei AfD. Die Hintergründe der Tat lassen sich nun mal nicht für migrantenfeindliche Hetze ausschlachten.
Bei der Todesfahrt in der Mannheimer Innenstadt gehen die Ermittler nicht von einem politischen Hintergrund aus. Das teilten die Staatsanwaltschaft Mannheim und die Polizei in einer gemeinsamen Erklärung mit. Zwei Personen seien tödlich und fünf schwer verletzt worden, heißt es in der Mitteilung. Nach dem Horror von Mannheim steht inzwischen fest: Der verdächtige Autofahrer ist Deutscher. Bei dem nach der Todesfahrt von Mannheim festgenommenen Mann handelt es sich nach Angaben von Baden-Württembergs Innenminister Thomas Strobl (CDU) um einen 40-jährigen Deutschen mit Wohnsitz in Rheinland-Pfalz. Wie die Mannheimer Polizei mitteilte, steht inzwischen fest, dass er als Einzeltäter handelte.
Hintergrund der Todesfahrt ist wohl eine psychische Erkrankung, teilte der zuständige Staatsanwalt in Mannheim mit. Der Fahrer des Wagens war nach SWR-Informationen deutschen Sicherheitsbehörden bislang nicht im Zusammenhang mit Extremismus oder Terrorismus aufgefallen. Er soll aber schon früher psychisch auffällig gewesen sein.
Der Täter war bei der Polizei kein unbeschriebenes Blatt. Es gebe ein paar Vorstrafen, die lange zurücklägen, sagte Staatsanwalt Romeo Schüssler in Mannheim. Dabei gehe es um eine Körperverletzung, für die er eine kurze Freiheitsstrafe verbüßt habe vor über zehn Jahren, außerdem ein Fall von Trunkenheit im Verkehr. Bei der letzten Tat handle es sich um ein Delikt im Bereich von Hate Speech aus dem Jahr 2018. Er habe einen entsprechenden Kommentar auf Facebook abgesetzt und sei deshalb zu einer Geldstrafe verurteilt worden.
Auffällig bei den öffentlichen Reaktionen: Politiker fast aller Parteien – sogar die wiederbraune CDU – brachten ihr Entsetzen zum Ausdruck. Nicht so die blaue Nazipartei AfD. Die Hintergründe der Tat lassen sich nun mal nicht für migrantenfeindliche Hetze ausschlachten.
Wenn man als Gitarrist mit einem Banjo zusammenspielt, dann spielt sich das meistens über die Akkorde G-Dur, C-Dur und D-Dur ab. In diesem Tutorial lernst du einige typische Licks, die dein Gitarrenspiel nach Bluegrass klingen lassen, kennen.
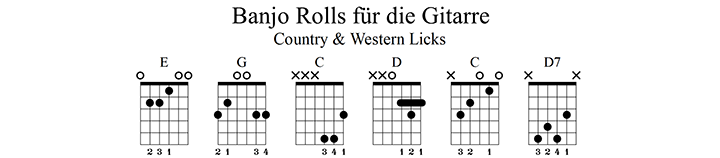
Das Akkordmaterial
Die vorliegenden Akkord-Diagramme geben dir einen Anhalt über die im Tutorial verwendeten Akkorde. Übe sie, bis du alle im flüssigen Wechsel greifen kannst. Beachte aber auch unbedingt den Fingersatz im jeweiligen Lick und passe deine Grifftechnik entsprechend an – nicht immer muss ein Akkord voll gegriffen werden!
Für alle Akkorde und Licks gilt: Übe zunächst in sehr langsamem Tempo und steigere dich erst, wenn alles sauber klappt.
Fingersatz für die Spielhand
p = Daumen
i = Zeigefinger
m = Mittelfinger
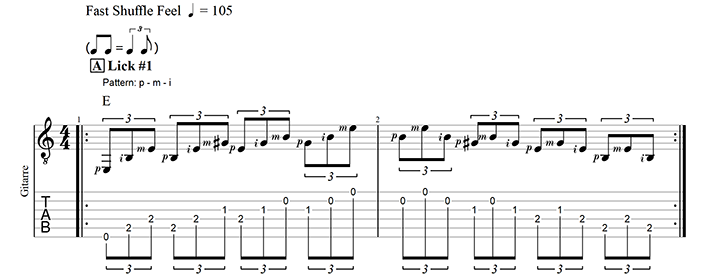
Lick #1 – eine Arpeggio-Roll über E-Dur
Dieses Lick eignet sich gut als Aufwärm-Training. Beachte unbedingt die Fingersätze der Greifhand.
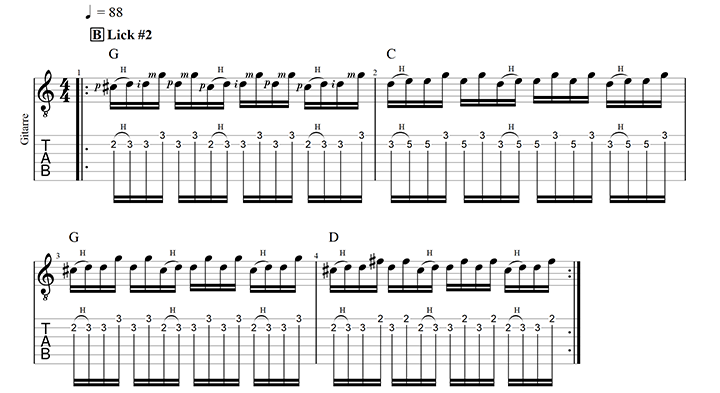
Lick #2 – Rock’n’Roll-style Banjo-Roll auf den hohen Saiten
Dieses Lick klingt besonders gut, wenn du es im höheren Tempo spielst. Übe es trotzdem zunächst in sehr langsamem Tempo und steigere dich erst, wenn alles sauber klappt.
Lick # 3 – ein melodiöses Roll mit Bass-Begleitung
Dieses Lick eignet sich gut für Bluegrass und Reels
Lick #4 – ein Roll für Reels, Bluegrass und Blues
Dieses Lick hat seine „schwere“ Zählzeit auf dem ersten Schlag eines Taktes. Es klingt auch sehr gut, wenn du die Bässe per Palm Mutingabdämpfst.
Lick #5 – ein melodiöses Riff mit Extras
Das war’s dann auch für heute! Lass‘ dir die Zeit zum Üben, die du brauchst, schludere nicht beim Draufschaffen und vor allem: Hab‘ Spaß!
Download:Dateien zum Blitz-Tutorial „Banjo Rolls für Gitarre“ Das Archiv enthält das Noten-/Tabulaturblatt als PDF, sowie alle Soundbeispiele als MP3 und Dateien zur Verwendung in Guitar Pro 8, MuseScore und MIDI-Anwendungen.