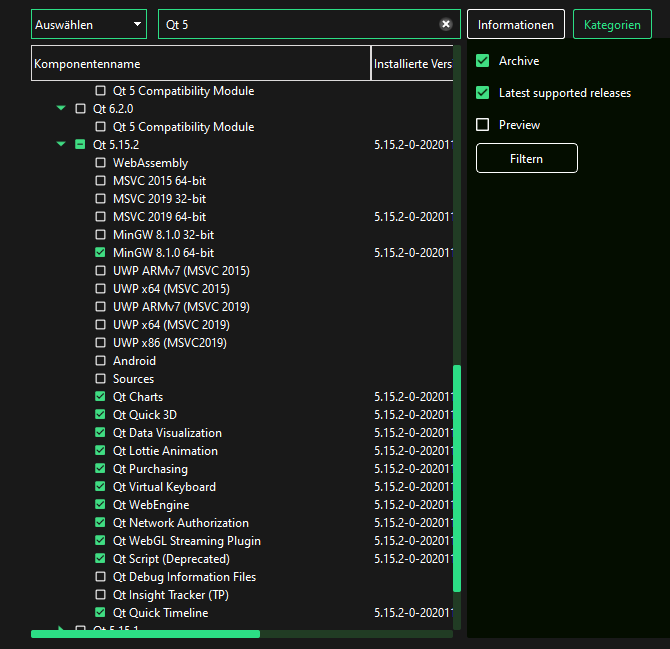
Norbert Roschauer ist eine lebende Legende unter den Blues-begeisterten Gitarrenlehrern Deutschlands – und das schon ein halbes Menschenleben lang. Mit „Simple Blues“ hat er Ende des letzten Jahres ein Lehrbuch für den Blues auf der akustischen Gitarre herausgebracht, das spannend, nachvollziehbar und didaktisch gut aufgebaut zugleich ist.
Das Werk führt den Einsteiger in 5 Abschnitten anhand zahlreicher gut gegliederter Übungen und Beispiele in die Welt des Blues-Pickings ein und darf meiner Meinung nach getrost als ein Standardwerk des Genres betrachtet werden – nicht nur für Einsteiger.
Neben den Basics vermittelt „Simple Blues“ dem lernwilligen Gitarrespieler auf 123 Seiten auch Rythmuswissen, erweiterte Picking-Techniken und den Umgang mit Open Tunings anhand von Dropped D – leicht verständlich und gut durchdacht.
Ich kann „Simple Blues“ jedem Gitarristen, der in den Blues eintauchen mag, unbedingt empfehlen. 🙂
Dieser Teil des Tutorials ist erst im Entstehen begriffen. Schau doch bitte auch später noch einmal vorbei!
Programme unter BlitzBasic/AmiBlitz3 werden „top down“ von oben nach unten abgearbeitet – doch es gibt Ausnahmen zu diesem Paradigma. Einige davon, wie z.B. Prozeduren, hast du bereits kennen gelernt.
Ein Programm, das stur der Reihe nach nur einen Befehl nach dem anderen abarbeitet, ist nicht sehr flexibel und wäre unnötig lang und anstrengend zu schreiben. Was ist, wenn bestimmte Befehlsfolgen mehrfach hintereinander ablaufen sollen? Oder wie sieht’s aus, wenn das Programm unterschiedlich auf verschiedene Bedingungen reagieren muss? Nun, für solche Fälle verfügt BlitzBasic über mächtige Kontroll- strukturen, die Fallunterscheidungen und bedingte Verzweigungen genauso ermöglichen, wie Wiederholungsschleifen – und darum geht es in diesem Teil des Tutorials.
Bedingungen auswerten
Als Programmierer steht man häufig vor dem Problem, dass das Programm mit unterschiedlichen Reaktionen auf bestimmte Bedingungen reagieren muss. BlitzBasic bringt für diesen Zweck verschiedene Kontrollstrukturen mit, die alle auf unterschiedliche Bedingungen hin zu unterschiedlichen Programmteilen verzweigen.
If … Then … Else … EndIf
Die If-Anweisung kommt gleich in mehreren Geschmacksrichtungen:
Variante 1 reagiert auf eine Bedingung und wenn diese zutrifft, so werden die Befehle im Anweisungsblock ausgeführt. Trifft die Bedingung nicht zu, dann wird die if-Anweisung übersprungen und das Programm danach fortgesetzt.
Variante 2 reagiert auf eine Bedingung und wenn diese zutrifft, so werden die Befehle im Anweisungsblock ausgeführt. Trifft die Bedingung nicht zu, dann wird der Anweisungsblock im Else-Teil abgearbeitet und das Programm danach fortgesetzt.
Die Varianten 1 und 2 benötigen das Schlüsselwort EndIf, um abgeschlossen zu sein.
Variante 3 reagiert auf eine Bedingung und wenn diese zutrifft, so wird der darauf folgende Befehl ausgeführt. Trifft die Bedingung nicht zu, dann wird die if-Anweisung übersprungen und das Programm danach fortgesetzt. Diese Variante benötigt nicht das Schlüsselwort EndIf.
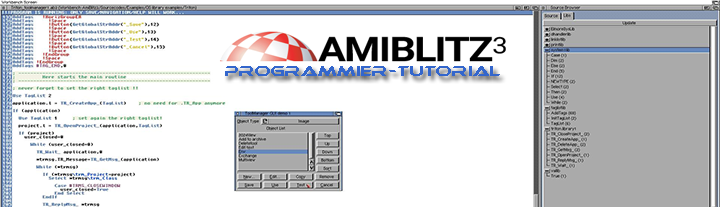
Bedingungen können einfache Vergleiche, aber auch komplizierte, zusammengesetzte Ausdrücke sein. Verdeutlichen wir uns die Zusammenhänge mit dem Listing „if.ab3“:
; ----------------------------
; File: if.ab3
; 3 x if-Anweisung
; Version: 1.0
; ----------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"if 1.0 (\\__DATE_GER__)"}
DEFTYPE .b myInput ;Globale Variablen deklarieren
; -- Benutzer-Eingabe --
Print "Gib entweder 0 oder 1 ein: "
myInput.b = Edit(1)
NPrint ""
; -- Auswertung --
; Variante 3
If (myInput.b <> 0) AND (myInput.b <> 1) Then NPrint "Falsche Zahl!"
If (myInput.b = 0) Then NPrint "Selber Null!"
; Variante 1
If myInput.b = 1
NPrint "Einmal ist keinmal!"
EndIf
If myInput.b = 0
NPrint "Eine große Null ist fast schon eine kleine Eins."
NPrint "Die Eins wolltest du wohl nicht haben?"
EndIf
; Variante 2
If myInput.b = 1
NPrint "Die Null wolltest du wohl nicht haben?"
Else
NPrint "Kannst du auch was richtig?"
EndIf
End
Ausgabe:
|- Gültige Zahl: 0 -|
Gib entweder 0 oder 1 ein: 0
Selber Null!
Eine große Null ist fast schon eine kleine Eins.
Die Eins wolltest du wohl nicht haben?
Kannst du auch was richtig?
|- Gültige Zahl: 1 -|
Gib entweder 0 oder 1 ein: 1
Einmal ist keinmal!
Die Null wolltest du wohl nicht haben?
|- Ungültige Zahl -|
Gib entweder 0 oder 1 ein: 9
Falsche Zahl!
Kannst du auch was richtig?
Programmanalyse:
Unser Programm fordert vom Benutzer die Eingabe von Null oder Eins an (Zeile 16) und gibt dann auf der Basis von Entscheidungen bestimmte Meldungen aus.
Zeile 21 prüft mittels einer einzeiligen If-Anweisung und einer aus zwei Teilbedingungen bestehenden Bedingung, ob die eingegebene Ziffer den gestellten Anforderungen entspricht. dabei verwenden wir die logischen Vergleichsoperatoren <> und And, um die beiden Teilbedingungen zu prüfen und miteinander zu verknüpfen. Das liest sich so:
WENN die Eingabe ungleich Null UND die Eingabe ungleich Eins ist, DANN sage "Falsche Zahl!"
Wir werden gleich noch intensiver über Vergleichsoperatoren sprechen – bis dahin merke dir: Der Operator für „ungleich“ ist <>, der Operator für das logische UND ist And. Trifft die Bedingung nicht zu, so fährt das Programm in Zeile 22 fort.
Zeile 16 liest mittels des Befehls Edit(1) die Benutzereingabe ein. Der Parameter „(1)“ legt fest, dass der Benutzer nur eine Ziffer eingeben darf.
Zeile 22 prüft mittels einer einzeiligen If-Anweisung und der Bedingung „ist die Eingabe identisch mit der Ziffer Null“, ob die Null gewählt wurde und gibt in diesem Fall die Meldung „Selber Null!“ aus. Andernfalls fährt das Programm in Zeile 25 fort. Zur Überprüfung der Bedingung kommt der Gleicheitsoperator „=“ zum Einsatz: If myInput.b = 0 Merke: Das Gleichheitszeichen ist kontextabhängig entweder der Zuweisungs- operator (z.B. Zahl = 42), oder aber der Gleichheitsoperator.
die Zeilen 25 bis 27 stellen ein einfaches If … EndIf-Konstrukt dar, zwischen dem der Anweisungsblock steht. Der besteht hier allerdings aus nur einer Anweisung. Wenn die Bedingung „Ziffer = 1“ erfüllt ist, wird eine Meldung ausgegeben.
die Zeilen 29 bis 32 funktionieren identisch. Hier besitzt der Anweisungsblock zwei Anweisungen.
Zeilen 35 bis 39 bestehen aus einem If … Else … EndIf-Konstrukt: WENN die Bedingung erfüllt ist, gib eine Meldung aus, ANDERNFALLS gib eine andere Meldung aus.
So richtig rund läuft unser Programm aber noch nicht. Wir möchten, das die Meldung „Kannst du auch was richtig?“ nur bei einer Fehleingabe ausgegeben wird. Eine Lösungsmöglichkeit wäre es, anstatt einer einzeiligen If … Then …-Anweisung eine If … EndIf-Anweisung zu verwenden und beide Ausgaben in den Anweisungsblock zu packen:
...
If (myInput.b <> 0) AND (myInput.b <> 1)
NPrint "Falsche Zahl!"
NPrint "Kannst du auch was richtig?"
EndIf
...
Die zweite – kompliziertere – Möglichkeit besteht im Verschachteln von If-Konstrukten.
Verschachtelte If-Anweisungen
Betrachte dir die folgende Programmsequenz mit ineinander verschachtelten If-Anweisungen:
...
If (myInput.b <> 0) AND (myInput.b <> 1) ; äußere Bedingung
NPrint "Falsche Zahl!"
If myInput.b > 1 ; innere Bedingung
NPrint "Kannst du auch was richtig?"
EndIf
Endif
...
Hier wird zunächst die äußere Bedingung geprüft und nur wenn sie zutrifft, dann wird die innere Bedingung abgearbeitet. Sie benutzt den Vergleichsoperator „größer als“ (>), um festzustellen, ob eine andere Ziffer als 0 oder 1 eingegeben wurde. Solche Verschachtelungen kann man natürlich noch viel weiter vertiefen. Ich rate dir allerdings dringend davon ab. Tiefe Verschachtelungen werden schnell unübersicht- lich und sind fehleranfällig. Nur in Ausnahmefällen sollte man mehr als zwei Verschachtelungen vornehmen.
Select … Case … End Select
Die Select … Case … End Select-Strukturen sind oft der beste Weg, um einfache Informationen zu verarbeiten, die von einem Benutzer kommen. Für jedes Case können in einem Anweisungsblock mehrere Anweisungen hintereinander abgearbeitet werden.
Schablone:
SelectAusdruck ; kann eine Variable, Konstante oder Rückgabewert sein
CaseWert 1
... Anweisungsblock ...
CaseWert 2
... Anweisungsblock ...
Caseweitere Werte
... usw ...
Default
... Anweisungsblock ...
(wird ausgeführt, wenn keine andere Bedingung zutraf)
End Select
Das Konstrukt funktioniert folgendermaßen:
Dem Schlüsselwort Selectwird ein Ausdruck übergeben. Dieser kann der Wert einer Variablen, Konstanten, der Rückgabewert einer Funktion oder eine komplexe Bedingung sein.
Dem Schlüsselwort Casewird ein möglicher Wert dieses Ausdrucks als Bedingung übergeben. Diese wird geprüft. Trifft sie zu, dann wird der zugehörige Anweisungsblock abgearbeitet. Trifft sie nicht zu, dann wird das Programm mit dem nächsten Case fortgesetzt.
Das Schlüsselwort Defaultist optional. Der Anweisungsblock nach Default wird abgearbeitet, wenn keine der vorherigen Bedingungen zutraf.
Das Konstrukt wird mit dem Schlüsselwort End Select abgeschlossen.
Auch Select-Konstrukte können ineinander verschachtelt werden.
Mit Select … Case-Konstrukten können wir unser Beispiel if.ab3 bequem so umbauen, dass es genau die Ausgaben liefert, die wir erwarten. Das Listing „select.ab3“ verdeutlicht das:
; ------------------------------
; File: select.ab3
; Select ... Case ... End Select
; Version: 1.0
; ------------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"select 1.0 (\\__DATE_GER__)"}
DEFTYPE .b myInput ;Globale Variablen deklarieren
; -- Benutzer-Eingabe --
Print "Gib entweder 0 oder 1 ein: "
myInput.b = Edit(1)
NPrint ""
; -- Auswertung --
Select myInput.b
Case 0
NPrint "Selber Null!"
NPrint "Die Eins wolltest du wohl nicht haben?"
NPrint "Eine große Null ist fast schon eine kleine Eins."
Case 1
NPrint "Einmal ist keinmal!"
NPrint "Die Null wolltest du wohl nicht haben?"
Default
NPrint "Falsche Zahl!"
NPrint "Kannst du auch was richtig?"
End Select
End
Ganz schön kurz und viel übersichtlicher, oder?
Programmanalyse:
in Zeile 16 lesen wir die Benutzereingabe ein. Diese wird in den Zeilen 21 bis 31 dann mit einem Select … Case … Default-Konstrukt ausgewertet.
Zeile 21 bestimmt, dass die Variable myInput.b durch Select ausgewertet werden soll.
Wenn der Wert der Variablen myInput.b gleich 0 ist, so wird das Case in Zeile 21 abgearbeitet.
Wenn der Wert der Variablen myInput.b gleich 1 ist, so wird das Case in Zeile 25 abgearbeitet.
Wenn der Wert der Variablen myInput.b weder 0, noch 1 ist, dann wird Default in Zeile 28 abgearbeitet.
Select … Case-Konstrukte eigenen sich z.B. ideal, um Benutzermenüs aufzubauen, wie das folgende Listing „menu.ab3“ zeigt:
; ------------------------------
; File: menu.ab3
; Select ... Case ... End Select
; Version: 1.0
; ------------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"select 1.0 (\\__DATE_GER__)"}
DEFTYPE .b mySelection ;Globale Variablen deklarieren
DEFTYPE .s myQuit
; -- Titel --
ANFANG :
NPrint "**************************"
NPrint "* Menueauswahl *"
NPrint "* ============ *"
NPrint "* Pizza - 1 - *"
NPrint "* Pasta - 2 - *"
NPrint "* Leberwurst - 3 - *"
NPrint "* *"
NPrint "* Programm beenden - 0 - *"
NPrint "**************************"
; -- Benutzer-Eingabe --
Print "Deine Wahl: "
mySelection.b = Edit(1)
NPrint ""
Select mySelection.b
Case 0
Print "Programm beenden? (j/n): "
myQuit.s = Edit$(1)
Select myQuit.s
Case "j"
End
Case "J"
End
Default
NPrint "Das Programm wird fortgesetzt..."
NPrint ""
Goto ANFANG
End Select
Case 1
NPrint "Du hast Pizza bestellt."
NPrint "Weiter: Maustaste"
MouseWait
NPrint ""
Goto ANFANG
Case 2
NPrint "Du hast Pasta bestellt."
NPrint "Weiter: Maustaste"
MouseWait
Goto ANFANG
Case 3
NPrint "Du willst Leberwurst."
NPrint "Weiter: Maustaste"
MouseWait
NPrint ""
Goto ANFANG
Default
NPrint "Falsche Eingabe!"
NPrint "Weiter: Maustaste"
MouseWait
NPrint ""
Goto ANFANG
End Select
End
Das Listing verwendet drei bisher unbekannte Elemente: Eine Sprungmarke und die Befehl Goto und MouseWait. Wir gehen nachher nochmal genauer auf die ersten beiden Elemente ein.
Programmanalyse:
Am Anfang wird das Menü ausgegeben und der Benutzer zu einer Eingabe aufgefordert, dann verzweigen wir mittels Select … Case … Default-Konstrukt zur Ausgabe einer passenden Meldung. Beachte das verschachtelte Select … Case … Default-Konstrukt bei der Sicherheitsabfrage zum Verlassen des Programms!
die Zeilen 16 bis 28 bilden das Menü und verlangen eine Benutzereingabe.
die Sprungmarke in Zeile 16 dient dazu, mittels des Goto-Befehls nach einer Ausgabe das Menü neu zu zeichnen.
die Zeilen 31 bis 66 bilden das Herzstück des Programms – hier wird im einem Select … Case … Default-Konstrukt die Benutzereingabe ausgewertet und auf sie reagiert.
das Case 0 in Zeile 32 reagiert auf die Eingabe der Ziffer 0, ist somit fürs Beenden des Programms (mit Sicherheitsabfrage) zuständig und fordert in Zeile 34 vom Benutzer eine Bestätigung an, die in der Variablen myQuit.s abgelegt wird.
Zeile 35 wertet diese Bestätigung mittels eines weiteren Select … Case … Default-Konstrukts aus und prüft ob ein „j“ oder ein „J“ eingegeben wurde (Zeilen 36 und 38). Trifft eins der Beiden zu, so wird das Programm beendet, andernfalls wird der Default-Zweig in Zeile 40 ausgeführt und das Programm läuft weiter. Dabei springt es in Zeile 43 mit dem Befehl Goto zur Sprungmarke ANFANG. Danach wird das Programm nach der Sprungmarke fortgesetzt, was dazu führt, dass das Menü erneut aufgebaut wird.Diesen Programmabschnitt hätten wir auch mit einem If … Then … EndIf-Konstrukt lösen können, aber wenn wir schonmal dabei sind…
Case 1 in Zeile 45 veranlasst die Ausgabe der Pizza-Meldung und springt danach wieder zu ANFANG. Damit der Benutzer nicht sofort wieder mit dem Menü konfrontiert wird, warten wir mit dem Befehl MouseWait, bis er die linke Maustaste gedrückt hat.
Die beiden anderen Case-Anweisungen funktionieren synonym zu Case 1.
Schon ganz eindrucksvoll, aber es geht noch besser! Anstatt das Menü immer wieder nacheinander auszugeben wäre es doch schick, wenn es immer ganz oben in der Shell aufgehen würde!? Das geht – man muss der Shell dazu nur die Escape-Sequenz zum Löschen des Bildschirms senden. BlitzBasic verfügt leider nicht über einen entsprechenden Befehl, aber dafür besitzt AmiBlitz3 einen neuen Modus, der das Senden von Escape-Sequenzen erlaubt. Dafür musst du allerdings das Programm mit der Option OPTIMIZE 4 compilieren! Diese Methode ist nicht kompatibel zu BlitzBasic v2.1 und älter. Realisiert wird das Löschen des Bildschirms dann mittels zweier Print-Befehle:
Print "\\1B[1m":Print "\\1Bc"
Hinweis: Bisher haben wir Anweisungen immer nur einzeilig geschrieben – jede Anweisung für sich. BlitzBasic erlaubt es jedoch auch, mehrere eigenständige Anweisung in einer Zeile unterzubringen. Dazu trennt man die Anweisungen durch einen Doppelpunkt.
Es gibt aber auch eine abwärtskompatible Lösung (besten Dank an Rob Cranley):
Print Chr$($0c) ; kompatibel zu BlitzBasic v2.1
Um das Listing um die Möglichkeit, den Bildschirm zu löschen, zu erweitern, gehst du wie folgt vor:
Ändere in Zeile 6 OPTIMIZE 1 auf OPTIMIZE 4 (nur für AmiBlitz3-kompatible Lösung)
füge nach Zeile 16 eine Leerzeile ein und trage dort die Print-Befehle mit den erforderlichen Escape-Sequenzen ein: Print „\\1B[1m“:Print „\\1Bc“ oder Print Chr$($0c) (kompatibel zu BlitzBasic v2.1)
Lösche die Zeilen 41 und 42 – ihre Ausgaben wären beim Löschen des Bildschirms ohnehin nicht mehr sichtbar.
Wenn du in einem Programm öfter den Bildschirm löschen möchtest, dann ist es übersichtlicher, die Escape-Sequenz in einer Variablen abzulegen und diese dann bei Bedarf aufzurufen:
Schreibe ein Programm zur Berechnung der Grundrechenarten, der Potenz zweier Zahlen und lasse es bestimmen, ob die Division zweier Ganzzahlen einen Rest besitzt (Modulo)
Verwende für die Berechnungen Funktionen und rufe sie über ein Menü auf.
Verwende für die Benutzereingabe der beiden Zahlen ein Statement. Tipp: Lokale und globale Variablen, Schlüsselwort SHARED.
Lasse vor Aufruf der Funktion zur Division prüfen, ob der DivisorNull ist. Die Berechnung soll nur ausgeführt werden, wenn der Divisor ungleich Null ist – andernfalls soll seine Fehlermeldung ausgegeben und die Funktion nicht ausgeführt werden.
Die Modulo-Funktion soll Aussagen darüber treffen, ob eine Division mit oder ohne Rest erfolgt ist und anschließend das Ergebnis der Division zum Vergleich als Fließkommawert ausgeben.
Sorge dafür, dass das Programm so lange läuft, bis der Benutzer es beendet. Tipp: Sprungmarke, Goto.
Nehmen wir einmal an, du möchtest fünfzigmal hintereinander einen bestimmten Text ausgeben. Natürlich könntest du dafür fünfzigmal hintereinander eine entsprechende NPrint-Anweisung schreiben – aber das wäre umständlich. Ist aber auch nicht nötig, denn BlitzBasic stellt auch für dieses Problem verschiedene Kontrollstrukturen zur Verfügung, die im Fachjargon Wiederholungsschleifen genannt werden.
Rechner sind zum Rechnen da – das ist ihr Kerngeschäft und da bildet der Amiga keine Ausnahme. BlitzBasic/AmiBlitz3 bringt bereits eine große Anzahl an mathematischen Bibliotheksfunktionen für alle Anwendungsfälle mit, die sich bei Bedarf jederzeit um selbstgeschriebene, eigene Funktionen erweitern lassen – und darum geht es in diesem Teil unseres Tutorials.
Die Grundrechenarten
Um einfache Berechnungen anzustellen, bedarf es keiner umfangreichen Mathe-Bibliotheken und -funktionen. BlitzBasic beherrscht ohne weiteren Aufwand Addition (+), Subtraktion (-), Multiplikation (*) und Division (/). Um eine Berechnung durchzuführen genügt es, zwei Zahlen mit dem entsprechenden Operator zu verknüpfen und das Ergebnis einer Variablen zuzuweisen. Beispiele:
Tauchen in einem Term (einer Anweisung) unterschiedliche Rechenoperationen auf, so muss man die Priorität der einzelnen Operationen beachten. Die Hierarchie ist wie folgt aufgebaut:
Potenzierung
Multiplikation und Division („Punktrechnung“)
Addition und Subtraktion („Strichrechnung“)
Beachtet man diese Rangordnung nicht, so kann es zu unerwarteten Seiteneffekten aufgrund falscher Ergebnisse kommen. Beispiel:
Überrascht? Wir haben in diesem Beispiel die Faustregel „Punkt- vor Strichrechnung“ nicht beachtet und denken uns: 5 + 5 = 10, 10 * 3 = 30. Der Computer macht alles richtig und rechnet stattdessen: 5 * 3 = 15, 5 + 15 = 20.
Klammerung von Termen
Um die Priorität einer verketteten Berechnung zu ändern, setzt man runde Klammern entsprechend der gewünschten Priorisierung:
Jetzt werden tatsächlich 5 + 5 addiert, bevor die Multiplikation durchgeführt wird.
Die Wahl eines „passenden“ Datentyps
Wenn man das Ergebnis einer Berechnung einer Variablen zuweisen möchte, dann muss man sich bereits im Vorfeld Gedanken darüber machen, welche Art von Zahlen und Zahlengrößen dabei anfallen können. Die Zahl muss ja schließlich auch in die Variable hinein passen. Werden nur sehr kleine Zahlen als Ergebnis erwartet? Kann ich mich auf Ganzzahlen beschränken, oder sind Fließkommazahlen zu erwarten? Wie groß kann ein Ergebnis ausfallen, falls sich die Werte der Berechnung ändern?
Der Datentyp einer Variable bestimmt, ob eine abzulegende Zahl fehlerfrei dargestellt werden kann (siehe Anhang A) oder nicht. Ausschlaggebend ist dabei sein Wertebereich. Ist er zu klein bemessen, dann könnte die Variable überlaufen und falsche Resultate liefern. Bemisst man ihn zu groß, so verschwendet man Ressourcen. Weist man eine Fließkommazahl einem Ganzzahlen-Typen zu, dann gehen die Nachkommastellen verloren, was wiederum zu Fehlern im Programm führen kann. Gerade bei der Division zweier Zahlen muss z.B. regelmäßig mit einem Ergebnis in Form einer Fließkommazahl gerechnet werden. Du siehst, es erfordert Hirnschmalz. Der Leitsatz zur Wahl eines passenden Datentyps könnte etwa so lauten: „So viel wie nötig, aber so wenig wie möglich“.
Das Listing „calc1.ab3“ führt die Grundrechenarten vor und zeigt kleine Unterschiede zwischen Berechnungen mit Ganzzahlen und solchen mit Fließkommazahlen auf:
in den Zeilen 13 bis 20 deklarieren und initialisieren wir, wie gewohnt, die Variablen des Programms. Verwendet werden Ganzzahlenwerte (Integerwerte) vom Typ Long und große Fließkommawerte vom Typ Float.
die Zeilen 23 bis 28 führen Additionen durch und geben anschließend deren Summen aus. Dabei addiert die Berechnung in Zeile 24 zwei Ganzzahlen und weist die Summe einer Float-Variablen zu. Beachte: Die Ausgabe zeigt trotzdem lediglich eine Ganzzahl an.
die Ausgabe in Zeile 27 erfolgt mit einer direkt an NPrint übergebenen, mittels Str$ in einen String umgewandelten Berechnung mit zwei Fließkommazahlen. Die Ausgabe zeigt hier, wie erwartet, eine Fließkommazahl als Ergebnis an.
Analog zum Gesagten erfolgt in den Zeilen 31 bis 38 die Subtraktion, in den Zeilen 39 bis 44 die Multiplikation und in den Zeilen 46 bis 52 die Division.
Erinnerung:Print und NPrint erwarten bei der Verwendung von aus Zahlen und Strings zusammengesetzten Parametern, dass die Zahlen in einem zusammengesetzten String ebenfalls als String vorliegen! Darum wandeln wir solche Zahlen per Str$ um.
Anstatt des „großen“ Typs Float hätten wir hier auch den kleineren Typ Quick verwenden können. Beide Typen unterscheiden sich allerdings sowohl in ihrem Wertebereich, als auch in ihrer Genauigkeit bezüglich ihrer Anzahl an Nachkommastellen. Das kurze Listing „floatcalc.ab3“ veranschaulicht die Unterschiede beider Datentypen:
Zum Ablauf dieses Programms gibt es nicht viel zu sagen. Wir initialisieren die Variablen jeweils mit den gleichen Inhalten. Quick liefert als Ergebnis der Berechnung eine Zahl mit 4 Nachkommastellen, bei Float sind es 6.
Aufgaben:
Versuche spaßeshalber einmal, alle Variablen mit zusätzlichen Nachkommastellen zu initialisieren und compiliere das Programm erneut. Beachte die Fehlermeldung des Compilers.
Initialisiere eine Quick-Variable mit dem Wert 37900001.5123456 und compiliere das Programm. Was sagt der Compiler?
Schreibe ein Programm mit einer Quick-Variablen und weise dieser den Wert 32767.1 zu. Gib diesen Wert aus. Addiere nun 1.0 zum Wert und gib die Variable erneut aus. Was passiert?
Modulo – der Rest einer Division
Modulo ist eine mathematische Operation, die den Rest einer ganzzahligen Division bezeichnet. Programmierer verwenden diese Operation z.B. zur Prüfung, ob eine ganzzahligen Division einen Nachkommaanteil besitzt. Ist dies der Fall, so liefert die Operation den Wert 1 zurück, andernfalls 0. BlitzBasic verwendet den Befehl MOD, um die Operation durchzuführen. Beispiele:
rest.w = 4 MOD 3 ; Ergebnis: 1, es gibt einen Rest
rest.w = 4 MOD 2 ; Ergebnis: 0, es gibt keinen Rest
Das Listing „modulus.ab3“ demonstriert die Verwendung:
; -----------------------
; File: modulus.ab3
; Rest einer Division
; Version: 1.0
; -----------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"modulus 1.0 (\\__DATE_GER__)"}
DEFTYPE .w modulus, zahl1, zahl2
; Werte eingeben
NPrint "Rest einer Division testen"
NPrint "Gib zwei Ganzzahlen ein!"
Print "Erste Zahl: "
zahl1 = Edit(10)
Print "Zweite Zahl: "
zahl2 = Edit(10)
NPrint""
; Modulus-Operation
modulus = zahl1 MOD zahl2
; Auswertung
If (modulus = 0)
NPrint "Die Division hat keinen Rest."
Else
NPrint "Die Division weist einen Rest auf."
EndIf
End
Programmanalyse:
in den Zeilen 16 bis 20 fragen wir den Benutzer nach der Eingabe von zwei Ganzzahlen und lesen diese jeweils in den Zeilen 18 und 20 ein. Dazu verwenden wir die Funktion Edit(), das Gegenstück für Zahlen zu Edit$() (Letzteres haben wir bereits in anderen Programmen verwendet, um Zeichenketten einzulesen). Der Parameter in Klammern gibt dabei die Anzahl zulässiger Ziffern an – hier sind es 10.
Zeile 24 führt die Modulus-Operation aus und weist deren Resultat der Variablen modulus zu.
in den Zeilen 27 bis 31 untersuchen wir mit einer if…else…endif-Abfrage, ob ein Rest vorliegt und geben eine entsprechende Meldung aus. WENN der Wert der Variablen modulus Null beträgt, so gibt es keinen Rest – ANDERNFALLS existiert ein Rest (später mehr zu vergleichenden Abfragen).
Potenzierung
Eine Potenz ist das Ergebnis des Potenzierens (der Exponentiation), das wie das Multiplizieren seinem Ursprung nach eine abkürzende Schreibweise für eine wiederholte mathematische Rechenoperation ist. Wie beim Multiplizieren ein Summand wiederholt addiert wird, so wird beim Potenzieren ein Faktor wiederholt multipliziert. Dabei heißt die Zahl, die zu multiplizieren ist, Basis. Wie oft diese Basis als Faktor auftritt, wird durch den Exponenten angegeben. Man schreibt:
BlitzBasic verwendet zur Potenzierung das Zeichen „^“. Auch diese Rechenoperation schauen wir uns an einem Beispiel an – „power.ab3“:
Potenzieren:
Gib zwei Ganzzahlen ein!
Basis: 2
Faktor: 16
Die Potenz von 2 hoch 16 ist 65536
Zum Programmaufbau gibt es nicht viel zu sagen. Den Datentyp der Variablen haben wir mit Long Word (.l) angegeben – Word (.w) wäre zu klein, da beim Potenzieren sehr große Zahlen entstehen können. Den Ablauf dieses Programms solltest du inzwischen ohne weitere Erläuterung verstehen können.
Prozeduren, Statements und Funktionen
Eine Prozedur (Procedure) ist eine Möglichkeit, Routinen (wie z.B. wiederkehrende Berechnungen) in eigenständige Teile des Programms zu „verpacken“. Sobald eine Routine in eine Prozedur verpackt ist, kann sie von deinem Hauptcode aus aufgerufen werden. Parameter können übergeben werden, und ein optionaler Wert wird an den Hauptcode zurückgegeben. Da eine Prozedur ihren eigenen lokalen Variablenbereich enthält, kannst du sicher sein, dass keine deiner Haupt- oder globalen Variablen durch den Aufruf der Prozedur verändert wird. Diese Eigenschaft bedeutet, dass Prozeduren sehr portabel sind, d.h. sie können in andere Programme portiert werden, ohne dass es zu Konflikten mit dort verwendeten Variablennamen gibt.
Einfache Prozeduren geben keine Werte an ihren Aufrufer zurück und werden als Statements bezeichnet. Prozeduren, die Werte zurück liefern, heißen unter BlitzBasic Funktionen. Procedure ist also lediglich der Oberbegriff für Beides.
Funktionen und Statements unter BlitzBasic haben die folgenden Eigenschaften:
Die Anzahl der Parameter ist auf 6 begrenzt.
Gosub und Goto zu Labels außerhalb des Codes einer Prozedur sind streng verboten.
Alle lokalen Variablen, die innerhalb einer Prozedur verwendet werden, werden bei jedem Aufruf neu initialisiert. Ihre Werte sind also nur so lange gültig, wie die Prozedur läuft.
Statements
Ein Statement definiert man nach folgender Schablone:
StatementName{Parameter}
... Anweisungen ...
End Statement
Der Name des Statements ist frei wählbar. Einem Statement können innerhalb der geschweiften Klammern bis zu 6 Parameter mitgegeben werden, die Statement-intern weiterverarbeitet werden. Einem Statement muss nicht zwingend ein Parameter übergeben werden – in dem Fall bleiben die geschweiften Klammern leer. Variablen innerhalb eines Statements sind stets lokal, d.h. nur innerhalb des Statements gültig – es sei denn, man macht sie mit dem Schlüsselwort SHARED allgemein zugänglich.
Das Listing „statement.ab3“ verwendet ein Statement, um den Fakultätsfaktor einer Zahl fünfmal auszugeben. Beachte, dass bei Verwendung der strengen Syntaxprüfung mittels OPTION 1 sämtliche Variablen im Vorfeld deklariert werden müssen! Außerdem müssen sie in diesem Fall mit ihrem vollen Namen inklusive der Extension(hier: .l) angesprochen werden.
; ----------------------------
; File: statement.ab3
; Funktion ohne Rueckgabewert
; Version: 1.0
; ----------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"statement 1.0 (\\__DATE_GER__)"}
DEFTYPE .l k ; globale Variable: k
; ein Statement definieren
Statement fact{n.l}
DEFTYPE .l a, k ; Lokale Variablen: a, k
a.l = 1
For k.l = 2 To n.l
a.l = a.l * k.l
Next
NPrint a
End Statement
; Hauptteil
For k.l = 1 To 5
fact{k.l} ; Aufruf des Statements
Next
End
Ausgabe:
1
2
6
24
120
Programmanalyse:
Zeile 12 deklariert die im Hauptteil (außerhalb des Statements) verwendete globale Variable als Long Word.
die Zeilen 15 bis 24 definieren das Statement fact{n.l}.
Zeile 15 ist der Kopf des Statements, bestehend aus dem Schlüsselwort Statement, dem Namen (fact) und der Parameterliste in geschweiften Klammern. Sie enthält nur einen Parameter: n. Beachte, dass aufgrund der strengen Syntaxprüfung der Parameter n mit einem Datentyp deklariert werden muss.
die Zeilen 16 bis 23 sind der Rumpf des Statements, der in Zeile 24 mit der Anweisung End Statement abgeschlossen wird.
Zeile 16 deklariert die lokalen Variablen des Statements als Long Word.
Zeile 18 initialisiert die lokale Variable a.l mit dem Wert 1.
in den Zeilen 19 bis 21 wird mittels einer for…next-Schleife (später mehr dazu!) der Wert der Variablen a.l mit sich selbst multipliziert.
der berechnete Wert wird in Zeile 23 ausgegeben.
Auch im Hauptteil ab Zeile 27 wird eine for…next-Schleife verwendet. Sie läuft fünf mal und ruft bei jedem Durchlauf einmal das Statement fact{n.l} auf. Würde man also den Zähler der Schleife erhöhen, so würden dementsprechend mehr Zahlen ausgegeben werden. Versuche es spaßeshalber: Ersetze die Zahl 5 in Zeile 27 mit der Zahl 10 und compiliere und starte das Programm erneut. Anmerkung: Das geht nur bis maximal zur Zahl 16 gut – ab 17 läuft die Variable über!
Funktionen
Im Gegensatz zu Statements liefern Funktionen über die Anweisung Function Return einen weiter verarbeitbaren Wert an den Aufrufer zurück. Eine Funktion definiert man nach folgender Schablone:
FunktionName{Parameter}
... Anweisungen ...
Function ReturnVariable ; Rückgabewert
End Funktion
Unser Beispiel für ein Statement lässt sich ohne Aufwand auch als Funktion realisieren. Dabei geben wir die berechnete Zahl nicht gleich direkt aus, sondern übergeben sie dem Aufrufer im Hauptteil des Programms. Das Listing „function.ab3“ zeigt, wie es funktioniert:
; ----------------------------
; File: function.ab3
; Funktion mit Rueckgabewert
; Version: 1.0
; ----------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"function 1.0 (\\__DATE_GER__)"}
DEFTYPE .l k ;Globale Variablen deklarieren
; Funktion definieren
Function fact{n.l}
DEFTYPE .l a, k ; Lokale Variablen deklarieren
a.l = 1
For k.l = 2 To n.l
a.l = a.l * k.l
Next
Function Return a.l ; Rueckgabewert
End Function
; Hauptteil
For k.l = 1 To 5
NPrint fact{k.l} ; Rueckgabewert drucken
Next
End
Die Programmlogik ist nahezu identisch zum vorherigen Listing – allerdings geben wir nun in Zeile 23 den berechneten Wert mit Function Return an den Aufrufer (NPrint) in Zeile 28 zurück.
Zugriff auf globale Variablen
Manchmal ist es notwendig, dass eine Prozedur auf eine oder mehrere globale Variablen eines Programms zugreifen kann. Zu diesem Zweck erlaubt der SHARED-Befehl, bestimmte Variablen innerhalb einer Prozedur als globale Variablen zu behandelt. Dazu ein schnelles Beispiel:
Statement example{}
SHARED k
NPrint k
End Statement
For k=1 To 5
example{}
Next
Per SHARED-Befehl teilst du dem Compiler mit, dass die Prozedur die globale Variable k verwenden soll, anstatt eine lokale Variable k zu erzeugen. Versuche dasselbe Programm ohne den SHARED-Befehl: Jetzt ist k innerhalb der Prozedur eine lokale Variable und wird daher jedes Mal 0 sein, wenn die Prozedur aufgerufen wird.
Rekursion
Der von den lokalen Variablen einer Prozedur verwendete Speicher ist nicht nur für die eigentliche Prozedur, sondern für jeden Aufruf der Prozedur reserviert. Jedes Mal, wenn eine Prozedur aufgerufen wird, wird ein neuer Speicherblock zugewiesen und erst nach Beendigung der Prozedur wieder freigegeben. Dies hat zur Folge, dass eine Prozedur sich selbst aufrufen kann, ohne ihre eigenen lokalen Variablen zu beschädigen. Das ermöglicht ein Phänomen, das als Rekursionbekannt ist. Hier ist eine neue Version der faktoriellen Funktion, die Rekursion verwendet:
; ----------------------------
; File: recursion.ab3
; rekursiver Funktionsaufruf
; Version: 1.0
; ----------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"recursion 1.0 (\\__DATE_GER__)"}
DEFTYPE .l n ;Globale Variablen deklarieren
; Funktion definieren
Function fact{n.l}
If n.l > 2 Then n.l = n.l * fact{n.l - 1} ; Rekursiver Aufruf
Function Return n.l ; Rueckgabewert
End Function
; Hauptteil
For n.l = 1 To 5
NPrint fact{n.l} ; Rueckgabewert drucken
Next
End
Dieses Beispiel beruht auf dem Konzept, dass die Berechnung der Fakultät einer Zahl eigentlich die Zahl, multipliziert mit dem Faktor von Eins weniger als die Zahl darstellt (Zahl – 1, vergl. Zeile 16).
Zusammenfassung
In diesem Teil des Tutorials haben wir gelernt
wie man unter BlitzBasic die Grundrechenarten und den Modulo-Operator verwendet und wie man Zahlen potenziert.
wie die Hierarchie der Rechenoperationen aufgebaut ist und wie man sie durch Klammerung verändern kann.
auf was es bei der Wahl des Datentyps für eine Variable ankommt.
wie man einen numerischen Wert mittels des Edit()-Befehls einliest.
das bei Zuweisung einer Fließkommavariablen an eine Ganzzahlvariable der Nachkommaanteil verloren geht.
das Prozeduren ein Oberbegriff für Statements und Funktionen sind.
das man Prozeduren maximal 6 Parameter übergeben kann.
das Statements im Gegensatz zu Funktionen keinen Rückgabewert liefern.
das Variablen innerhalb von Prozeduren lokaler Natur sind und nur innerhalb der jeweiligen Prozedur Gültigkeit besitzen.
Das lokale Variablen für andere Prozeduren und das Hauptprogramm nicht sichtbar sind, mittels des Schlüsselwortes SHARED aber sichtbar gemacht werden können.
das Prozeduren sich selbst rekursiv aufrufen können, wobei die Werte lokaler Variablen erhalten bleiben.
Ausblick
Im kommenden Teil des Tutorials werden wir uns Kontrollstrukturen zur Fallunterscheidung und Verzweigung, Wiederholungsschleifen, Wahrheitswerte und Vergleichsoperatoren näher betrachten.
Wer in den frühen Jahren der IT z.B. auf dem Commodore 64 in BASIC programmiert hat, der brauchte sich keine Gedanken um die Interna von Variablen und Konstanten zu machen. Es gab Variablen für Strings und Zahlen – und damit basta. Das hat sich mit modernen BASIC-Dialekten aus guten Gründen drastisch geändert.
Variablen belegen per se ein Stück zusammenhängenden Arbeitsspeicher (RAM) pro Stück. Aus heutiger Sicht ist es deshalb nicht effizient, für jede Variable eine gleich große Menge Arbeitsspeicher zu vergeuden. Manchmal möchte man nur mit sehr kleinen Zahlen arbeiten, ein andermal mit Fließkommazahlen und wieder ein anderes Mal benötigt man Platz für sehr große Zeichenketten (Strings). Das ist der Punkt, an dem Datentypenins Spiel kommen.
Wenn man für eine Variable immer nur so viel Speicher reserviert, wie tatsächlich gebraucht wird, dann verschwendet man weniger knappe Ressourcen (RAM) – aber es ergibt sich daraus noch ein weiterer Vorteil: Kleine Ganzzahlen werden vom Computer schneller verarbeitet, als z.B. große Fließkommazahlen.
Es ist auch unter BlitzBasic/AmiBlitz3 möglich, beim Schreiben von Programmen völlig darauf zu verzichten, sich mit Datentypen auseinanderzusetzen. Der Compiler geht dann intern einfach davon aus, dass er den Default-Datentyp verwenden soll. Unter AmiBlitz3 ist das QUICK (vergl. Anhang A – primitive Datentypen). Dieser Datentyp verbraucht entsprechend viel Ressourcen, da er ja groß genug für alle anfallenden Arten von Zahlen sein muss. Effizienter ist es da natürlich, sich die benötigte Größe der verwendeten Variablen vorher zu überlegen und sie mit einem passenden Datentyp zu deklarieren.
Variablen und ihr Datentyp
Eine Variable ist ein abstrakter Behälter für einen Wert, der bei der Ausführung eines Computerprogramms auftritt. Im Normalfall wird eine Variable im Quelltext durch einen Namen bezeichnet und hat eine Adresse im Speicher des Computers. Der durch eine Variable repräsentierte Wert (und gegebenenfalls auch die Größe) kann – im Unterschied zu einer Konstante – zur Laufzeit des Programms verändert werden. Variablen dienen also dazu, veränderbare Werte zu speichern.
Unter BlitzBasic/AmiBlitz3 definiert man eine Variable mittels des Schlüsselworts DEFTYPE nach dem folgenden Schema:
DEFTYPE .DatentypVariablenname
; -- Beispiel, deklariert eine Variable vom Typ String: --
DEFTYPE .saltesKinderliedaltesKinderlied = "Alle meine Entchen"
Es ist auch mögliche, eine Variable direkt, ohne DEFTYPE zu deklarieren:
altesKinderlied.s = "Alle meine Entchen"
Der Variablenname ist im Rahmen syntaktischer Vorgaben frei wählbar. Er sollte aussagekräftig den Zweck der Variablen wiedergeben („sprechender“ Name). Erlaubt sind alphanumerische Zeichen und der Unterstrich mit den folgenden Ausnahmen:
der Variablenname darf nicht gleichlautend mit einem Schlüsselwort sein.
das erste Zeichen darf keine Ziffer sein.
Umlaute sind nicht erlaubt.
Sonderzeichen außer dem Unterstrich sind nicht erlaubt. Ausnahmen: Sonderzeichen, die zur Identifizierung eines Datentypen gehören, dürfen am Anfang oder Ende des Variablennamens verwendet werden.
Der Datentyp legt den Speicherverbrauch einer Variablen fest.
Primitive Datentypen
BlitzBasic/AmiBlitz3 verfügt über 7 Basis-Datentypen – die sogenannten primitiven Datentypen. Die Sprache verfügt auch über die Möglichkeit, aus diesen Typen erweiterte, die sogenannten zusammengesetzten Datentypen, zu erstellen – doch dazu später mehr.
Jedem primitiven Datentyp ist ein bestimmter Wertebereich zu eigen, in dessen Rahmen er Zahlen und Zeichen darstellen kann. Die Größe dieses Wertebereich bestimmt seinen Speicherverbrauch (vergl. Anhang A – primitive Datentypen).
Byte (.b)
Dieser Datentyp verarbeitet kleine Ganzzahlen(Integerwerte) im Wertebereich von -128 bis +127 (-128 … 0 … +128) und verbraucht 1 Byte (8 Bits) Speicher. Er eignet sich z.B. gut als Zählervariable in kurzen Zählschleifen oder zur numerischen Darstellung des ASCII-Zeichensatzes. Beispiel: DEFTYPE .b kleinerZaehler = 0
Word (.w)
Dieser Datentyp verarbeitet mittelgroße Ganzzahlen im Wertebereich von -32768 bis +32767 (-32768 … 0 … +32767) und verbraucht 2 Bytes (16 Bits) Speicher. Beispiel:DEFTYPE .w fatNumber = 22000
Long / Long Word (.l)
Dieser Datentyp verarbeitet sehr große Ganzzahlen im Wertebereich von -231 bis +231 und verbraucht 4 Bytes (32 Bits) Speicher. Beispiel:DEFTYPE .l veryfatNumber = 4711081542
Quick (.q)
Dieser Datentyp verarbeitet kleine Fließkommazahlenim Wertebereich von -32768 bis +32767 unter Verwendung eines festen Dezimalpunkts und verbraucht 4 Bytes (32 Bits) Speicher, erlaubt bis zu 10 Nachkommastellen. Er ist schneller als die Emulation der Float-Typen in Software, aber langsamer als Integer und langsamer als Float-Typen auf einer Hardware-FPU. Beispiel:DEFTYPE .q smallFloatNumber = 4711.0815
Float (.f)
Dieser Datentyp verarbeitet große, einfachpräzise Fließkommazahlen im Wertebereich von -9*1018 bis +9*1018-1 und verbraucht 4 Bytes (32 Bits) Speicher. Er eignet sich besonders zur Verwendung als einfachpräzise Fließkommazahl, wie sie von den Standard-Fließkommabibliotheken des Amiga unterstützt wird und arbeitet mit +/-23bits+/-7 bits (10 Nachkommastellen)Dieser Datentyp ist sehr langsam in Software zu emulieren, aber sehr schnell, wenn Hardware-FPU verwendet wird. Er arbeitet langsamer als Ganzzahlen. Beispiel:DEFTYPE .f largeFloatNumber = 471143.0815
Double Float (.d)
Dieser Datentyp verarbeitet sehr große, doppeltpräzise Fließkommazahlen mit riesigem Wertebereich und verbraucht 8 Bytes (64 Bits) Speicher, 9 Nachkommastellen. Keine Software-Emulation möglich, daher muss eine Hardware-FPU vorhanden sein, um diesen Datentyp nutzen zu können! Nicht unterstützt in Blitz Basic 2.1 und früher. Langsamer als einfachpräzise Float-Typen. Typische Anwendungsfälle wären ein Programm zur Berechnung von Zinsen über lange Zeiträume oder eine ähnliche Banking-Software und alle Anwendungen, die wissenschaftliche Berechnungen mit Bedarf an hoher Rechengenauigkeit durchführen. Beispiel:DEFTYPE .d hugeFloatNumber = 471143.0815
Hinweis: Der Inhalt einer Variablen des neuen Datentyps Double Float kann nicht korrekt mit Print und NPrint ausgegeben werden! Beide Befehle liefern nur den ganzzahligen Anteil des Wertes einer Variablen dieses Datentyps – die Stellen nach dem Dezimalpunkt werden von beiden Befehlen unterschlagen. Derzeit unterstützt noch keine einzige BlitzLib diesen Datentypen, sodass er hier nur der Vollständigkeit halber aufgeführt ist! Wenn es vermeidbar ist, dann verwende diesen Datentyp nicht. Benutze stattdessen den Datentyp Float.
String (.s oder $)
Dieser Datentyp verarbeitet Zeichenketten aus 8-Bit-Zeichen im Speicher, die automatisch durch ein Nullzeichen (\0) abgeschlossen werden und verbraucht 4 Bytes (32 Bits). Beispiel 1:DEFTYPE .s myStringVar_1 myStringVar_1 = „Ich bin eine Zeichenkette!“ Beispiel 2: myStringVar_2.s = „Ich auch! Ich auch!“ Beispiel 3: myStringVar_3$ = „Und ich erst!“
Datentypen deklarieren
Bei der Deklaration von Datentypen unterscheidet man zwischen der Inline-Deklaration, der expliziten Deklaration und der globalen Festlegung eines bestimmten Default-Datentyps:
Inline: ergebnis.q = 4711.42 (die Variable wird mit dem angegebenen Typen – hier: QUICK – versehen und gleichzeitig mit einem Wert initialisiert)
Explizit: DEFTYPE .q ergebnis (die Variable – und nur diese – ist vom angegeben Typ. Hier: QUICK)
Global: DEFTYPE .q (alle nicht inline oder explizit deklarierten Variablen sind vom Typ, der hier angegeben wurde – in diesem Fall QUICK)
Das Listing „typesize.ab3“ demonstriert die Deklaration und Initialisierung der primitiven Datentypen und gibt deren Speicherbedarf in Bytes und Bits aus. Beachte, dass dieses Listing aufgrund der Verwendung des Datentyps DOUBLE FLOAT nur auf Amigas mit FPU compiliert werden kann!
Das Programm benutzt zwei neue Befehle: Str$() und SizeOf. Str$() wandelt einen numerischen Wert in einen String um. Sizeof liefert den Speicherverbrauch eines Datentyps in Bytes zurück.
Wir verwenden Str$, um den (numerischen) Rückgabewert von Sizeof einer String-Variable zuweisen zu können, die dann bei der Ausgabe durch Print und NPrint zusammen mit anderen Zeichenketten zu einer neuen Zeichenkette zusammengesetzt wird (String Concatenation).
Ablauf:
In Zeile 8 sorgen wir mit OPTIMIZE 3 dafür, dass neben der Optimierung für die MC68020 CPU auch die FPU verwendet wird (siehe Abschnitt „Optimierte Programme erzeugen“ im Artikel „Das erste Programm„). Das ist nötig, da wir u.a. den Datentyp DOUBLE FLOAT verwenden, der nur auf einer physisch vorhandenen FPU und erst ab AmiBlitz3 verwendet werden kann. BlitzBasic v2 und älter kennen diesen Datentypen nicht.
Zeile 9 schaltet die strenge Syntax-Prüfung ein, bei der alle Variablen vor ihrer ersten Verwendung per DEFTYPE deklariert werden müssen.
In den Zeilen 12 bis 18 deklarieren wir per expliziter Deklaration die im Programm verwendeten Variablen mit einem Datentyp.
Zeile 21 legt den Versions-String fest, der bei Abfrage mit dem DOS-Befehl version meinProgramm full in einer Shell Auskunft über die Versionsnummer und das Erstellungsdatum eines Programms gibt.
In den Zeilen 24 bis 30 weisen wir einigen der zuvor deklarierten Variablen Werte zu (Initialisierung).
Die Zeilen 33 bis 39 geben Speicherverbrauch und Inhalt der BYTE-Variablen byteVar aus:
In Zeile 33 wandeln wir die per SizeOf .b abgefragte Speichergröße (Anzahl Bytes) mittels Str$ in eine Zeichenkette um und weisen sie der String-Variablen byteRes zu.
In Zeile 34 verfahren wir analog, berechnen hier aber die Anzahl Bits durch Multiplikation mit dem Faktor 8 ( 1 Byte = 8 Bits). Das Ergebnis der Berechnung wird der String-Variablen bitRes zugewiesen.
In Zeile 35 geben wir per Print (ohne Zeilenvorschub) eine Teilmeldung aus. Sie setzt sich aus mehreren Teilstrings zusammen, die wir mit dem Verknüpfungsoperatur „+“ zu einem Gesamtstring für die Ausgabe zusammensetzen.
In Zeile 36 geben wir mit NPrint (mit Zeilenvorschub) einen weiteren zusammengesetzten String aus, der die Ausgabe der Speichergröße abschließt.
Zeile 37 druckt per Print eine weitere Meldung ohne Zeilenvorschub, an welche dann in Zeile 38 per NPrint der Wert (Inhalt) der Variablen byteVar angehängt und anschließend ein Zeilenvorschub ausgeführt wird.
Zeile 39 druckt mittels einem an NPrint übergebenen Leerstring einen weiteren Zeilenvorschub (ohne Text).
Analog zu den Zeilen 33 bis 39 werden in den Zeilen 41 bis 89 nacheinander die Speichergrößen und Inhalte für die übrigen Datentypen ausgegeben.
Das Programm endet in Zeile 91 mit der Anweisung End.
Speicherüberlauf
Wir haben gelernt, dass jeder Datentyp einen bestimmten Wertebereich besitzt, der die Größe der darstellbaren Inhalte einer Variablen bestimmt. Was aber, wenn dieser Wertebereich überschritten wird? Nun, in diesem Fall kommt es zum Speicherüberlauf. Bei numerischen Variablen hat das zur Konsequenz, dass ihr Inhalt nicht mehr mit dem vermuteten Wert übereinstimmt, was wiederum zu unvorhergesehenem Programmverhalten führt.
Wenn ein Wertebereich überschritten wird, so wird (normalerweise) kein Fehler erzeugt. Stattdessen wird der Wert auf das andere Ende des Wertebereichs umgeschlagen. Dies kann dazu führen, dass einige sehr schwer zu findende Fehler in deinen Code eingeschleust werden!
Ein Beispiel:Der Datentyp BYTE kann Ganzzahlen im Bereich zwischen -128 und + 127 darstellen. Wenn eine BYTE-Variable den Wert +127 besitzt und man addiert nochmal 1 dazu, so ist der Inhalt nicht, wie man vermuten könnte, +128, sondern -128. Das entspricht der unteren Grenze des Wertebereichs. Addiert man nun eine weitere 1 hinzu, so ist der Wert -127.
Im negativen Wertebereich verhält sich das genauso: Wenn eine BYTE-Variable den Wert -128 besitzt und man subtrahiert davon 1 weg, so ist der Inhalt nicht, wie man vermuten könnte, –129, sondern +127. Das entspricht der oberen Grenze des Wertebereichs. Subtrahiert man nun eine weitere 1, so ist der Wert +126. Das Listing „overflow.ab3“ verdeutlicht das eben Gesagte:
; ---------------------------------
; Listing: overflow.ab3
; Ueberlauf von Datentypen
; Version 1.0
; ---------------------------------
OPTIMIZE 1 ; MC68020+ Optimierungen
SYNTAX 1 ; strenger Syntax-Check
; -- Variablendeklaration mit DEFTYPE --
DEFTYPE .b byteVar
; Amiga Version string und das Compilerdatum
!version {"overflow 1.0 (\\__DATE_GER__)"}
; Variable initialisieren
byteVar = 127 ; positive Obergrenze
; Titel ausgeben
NPrint "=============="
NPrint "-- Overflow --"
NPrint "=============="
NPrint ""
; Wert ausgeben (positiver Bereich)
NPrint "positiver Wertebereich:"
Print "byteVar hat den Anfangswert: "
NPrint byteVar
NPrint "Addiere 1..."
byteVar = byteVar + 1
Print "byteVar hat nun den Wert "
NPrint byteVar
NPrint "Addiere weitere 1..."
byteVar = byteVar + 1
Print "byteVar hat nun den Wert "
NPrint byteVar
NPrint ""
; Wert zuruecksetzen auf Untergrenze
byteVar = -128
; Wert ausgeben (negativer Bereich)
NPrint "Negativer Wertebereich:"
Print "byteVar hat den Anfangswert "
NPrint byteVar
NPrint "Subtrahiere 1..."
byteVar = byteVar - 1
Print "byteVar hat nun den Wert "
NPrint byteVar
NPrint "Subtrahiere weitere 1..."
byteVar = byteVar - 1
Print "byteVar hat nun den Wert "
NPrint byteVar
NPrint ""
NPrint "Habe fertig."
End
Ausgabe:
==============
-- Overflow --
==============
positiver Wertebereich:
byteVar hat den Anfangswert: 127
Addiere 1...
byteVar hat nun den Wert -128
Addiere weitere 1...
byteVar hat nun den Wert -127
Negativer Wertebereich:
byteVar hat den Anfangswert -128
Subtrahiere 1...
byteVar hat nun den Wert 127
Subtrahiere weitere 1...
byteVar hat nun den Wert 126
Habe fertig.
Zum Programmablauf gibt es eigentlich nichts zu sagen – alle vorkommenden Anweisungen und Abläufe haben wir bereits besprochen.
Konstanten
Eine Konstante (von lateinisch constans ‚feststehend‘) in einem Computerprogramm ist ein Behälter für einen Wert, der nach der Zuweisung nicht verändert werden kann. Im Gegensatz zu Variablen ist der einmal festgelegte Wert einer Konstanten zur Laufzeit des Programms bindend.
Ein Rautezeichen (#) vor einem Variablennamen bedeutet, dass es sich um eine Konstante handelt (nicht mehr um eine Variable!) Der Wert einer Konstante ist immer eine Ganzzahl. Anders als in anderen Hochsprache, wie z.B. C/C++, kann man in BlitzBasic keine Konstanten mit anderen Datentypen definieren.
Konstanten haben die folgenden Eigenschaften:
Sie sind schneller als Variablen und benötigen keinen Speicherplatz.
machen Programme besser lesbar als Zahlen
Können in Assembler verwendet werden
Können mit bedingten Kompilierauswertungen verwendet werden
Können nur Integer-Werte enthalten
Erleichtert das Ändern einer konstanten Menge, die in einem Programm verwendet wird
Können nur über den Quellcode zur Kompilierzeit, aber NICHT zur Laufzeit geändert werden
Neben der Option, eigene Konstanten zu definieren, bringt BlitzBasic schon viele „eingebaute“ Konstante, wie bspw. die Kreiszahl Pi mit. Der wohl wichtigste Aspekt von Konstanten aus der Sicht eines BASIC-Programmierers ist aber wohl, dass alle „magischen Zahlen“, die im Code auftauchen, durch sinnvolle Worte wie #width ersetzt werden können („sprechende“ Namen!).
Das Listing „constants.ab3“ demonstriert die Verwendung von Konstanten.:
; -------------------------
; File: constants.ab3
; Zeigt die Verwendung von
; Konstanten
; Version: 1.0
; -------------------------
OPTIMIZE 1
SYNTAX 1
; Amiga Version String und das Compilerdatum
!version {"constants 1.0 (\\__DATE_GER__)"}
; Konstanten definieren:
#width = 5
#height = 5
; Variablen deklarieren:
DEFTYPE .w area
; Flaeche berechnen:
area = Abs(#width * #height)
; Ergebnis ausgeben:
Print "Die Flaeche aus " + Str$(#width)
Print " m mal " + Str$(#height)
NPrint " m betraegt " + Str$(Abs(area)) + " qm"
; Interne Konstante Pi ausgeben:
NPrint "Der Wert der Kreiszahl PI ist " + Str$(Pi)
End
Ausgabe:
Die Flaeche aus 5 m mal 5 m betraegt 25 qm
Der Wert der Kreiszahl PI ist 3.141592
Programmanalyse:
Das Programm verwendet den neuen Befehl Abs(). Er dient zur Umwandlung vorzeichenbehafteter Zahlen in vorzeichenlose Zahlen. Wir verwenden ihn zur Umwandlung des in der Variablen area gespeicherten Wertes, der als Produkt der Multiplikation zweier Konstanten sonst u.U. als negative Zahl ausgegeben werden könnte.
in den Zeilen 14 und 15 definieren wir die Konstanten #width und #height. Sie werden später zur Berechnung einer Fläche herangezogen.
in Zeile 18 deklarieren wir die Variable area als Variable vom Typ WORD.
in Zeile 21 berechnen wir die Summe der Fläche und weisen das Ergebnis der Variablen area zu.
die Zeilen 24 bis 26 dienen der Ausgabe der berechneten Werte. Dabei benutzen wir in Zeile 26 den zuvor erklärten Befehl Abs() zur Umwandlung des in area gespeicherten Wertes – just to make sure…
in Zeile 28 geben wir den Wert der internen Konstante Pi aus.
Das Programm endet mit Zeile 29.
Zusammenfassung:
In diesem Teil des Tutorials haben wir gelernt
Was Datentypen und Variablen sind, welche Datentypen es gibt und wie man Variablen deklariert und initialisiert.
das der neue Datentyp DOUBLE FLOAT nur mit AmiBlitz3 verwendet werden kann, eine vorhanden FPU voraussetzt – und das man ihn besser nicht verwenden sollte, was sich aber in einer späteren Version von AmiBlitz3 noch ändern kann.
was Konstanten sind und wie man sie definiert und verwendet.
dass Konstanten nur Ganzzahlen aufnehmen können und keinen Speicherplatz belegen.
Ausblick
Im nächsten Teil des Tutorials werden wir uns eingehend mit den Grundrechenarten und eigenen Funktionen unter BlitzBasic beschäftigen.
Erste Schritte mit BlitzBasic – Programmeingabe und Übersetzung
Jedes gute Tutorial für Programmierer beginnt mit dem wohl langweiligsten Programm auf diesem Planeten: Hello, World.
Bevor wir jedoch loslegen, gibt es noch etwas Organisatorisches zu erledigen: Wir brauchen ein Projektverzeichnis für die im Lauf dieses Tutorials anfallenden Dateien. Erstelle dazu zunächst ein Hauptverzeichnis irgendwo auf deiner Festplatte. Dort werden wir dann bei Bedarf weitere Unterordner für Projekte anlegen und unsere Listings dort passenden abspeichern.
Starte nun AmiBlitz3und gib im Editor-Fenster das folgende Listing buchstabengetreu, aber ohne Zeilennummern ein:
; ---------------------------
; Listing: hello1.ab3
; Hallo, Welt mit BlitzBasic
; Version 1.0
; ---------------------------
Print "Hallo, Welt!"
End
Speichere dein Programm (<Amiga> + <S>) unter dem Namen „hello1.ab3“ in deinem Projektverzeichnis 001_hello für unser Tutorial. Der Suffix „.ab3“ ist der Standard, um ein Listing als zu AmiBlitz3 gehörende Quelldatei zu kennzeichnen.
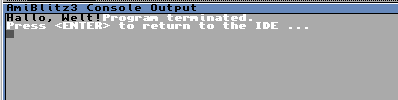
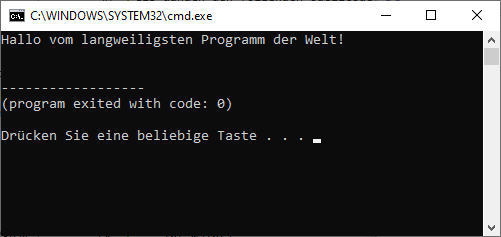
Stelle sicher, das die Option zum Starten des Debugger deaktiviert ist. Verwende die Tastenkombination <Amiga> + <#>, um dein Programm zu compilieren und zu starten. Du erhältst die folgende Ausgabe:
Betrachten wir uns Programm und Ausgabe einmal genauer:
Die Zeilen 1 bis 5 enthalten einen erklärenden Kommentar zum Programm. Kommentare werden in BlitzBasic mit dem Semikolon eingeleitet und gelten jeweils für eine Zeile. Alles, was in einem Kommentar steht, wird vom Compiler ignoriert.
Zeile 7 gibt mit dem Schlüsselwort Print die in Anführungszeichen gesetzte Meldung aus. Es erfolgt kein Zeilenvorschub!
Das Programm endet in Zeile 8 mit dem Schlüsselwort End.
Wenn du bereits Erfahrungen mit anderen BASIC-Dialekten gemacht hast, dann wirst du dich vielleicht wundern, warum nach dem Print-Befehl keine neue Zeile erzeugt wird. Nun, in BlitzBasic gibt es dafür den Befehl NPrint, der explizit einen Zeilenvorschub nach der Ausgabe erzeugt. Der Syntax ist mit dem von Print nahezu identisch.
Ändere unser erstes Programm nun so ab, dass es dem folgenden Listing entspricht und speichere es anschließend unter „hello2.ab3“ im gleichen Verzeichnis wie eben:
; ---------------------------
; Listing: hello2.ab3
; Hallo, Welt mit BlitzBasic
; Version 2.0
; ---------------------------
NPrint "Hallo, Welt!"
NPrint "Ich kann auch mit Zeilenvorschub..."
End
Drücke wieder <Amiga> + <#>, um dein Programm zu compilieren und zu starten. Diesmal sieht die Ausgabe des Programms so aus:
Ein Programm mit Variablen
Variablen dienen dazu bestimmte Werte, wie etwa Strings (Zeichenketten) oder Zahlenwerte, für die weitere Verwendung im Programm zwischen zu speichern. Sie werden im Arbeitsspeicher (RAM) angelegt. Sie besitzen einen Datentyp, der darüber entscheidet, welche Art von Wert eine Variable aufnehmen kann.
Lege für unser nächstes Projekt den Ordner 002_myname an. Gib dann das folgende Listing ein und speichere es als „myname1.ab3“ im eben erstellten Ordner.
; ---------------------------
; Listing: myname1.ab3
; Ein Programm mit Variablen
; Version 1.0
; ---------------------------
meinName$ = "Callimero" ; eine String-Variable deklarieren
NPrint "Hallo, Welt!"
Print "Mein Name ist "
Print meinName$
NPrint "."
NPrint "Nun ist es heraus..."
End
Ausgabe:
Hallo, Welt!
Mein Name ist Callimero.
Nun ist es heraus...
Program terminated.
Press <ENTER> to return to to the IDE...
Programmanalyse:
Unser Programm verwendet eine Variable vom Datentyp String. Das erkennt man schnell am an den Variablennamen angehängten Dollarzeichen ($). Stringvariablen nehmen alle Arten von alphanumerischen Zeichen und Leerstellen auf, sodass man ganze Sätze in einer String-Variablen ablegen kann. Eine String-Variable deklariert man, indem man ihr einen Variablenname mit angehängtem $ gibt. Bei einer vollständigen Definition weist man dann dieser Variablen mittels des Zuweisungsoperators (=) einen Text zu. Dieser wird zwischen Anführungszeichen gesetzt (In unserem Programm haben wir das in Zeile 7 getan). Beispiel:
meinString$ = "Alle meine Entchen"
Die Zeilen 1 bis 5 enthalten einen erläuternden Kommentar zum Programm.
in Zeile 7 deklarieren wir eine String-Variable (kenntlich am angehängten „$“ hinter dem Variablennamen) mit dem Inhalt „Calimero“. Hinter der Variablendeklaration steht ein erläuternder Kommentar.
Zeile 9 gibt die Meldung „Hallo, Welt!“, gefolgt von einem Zeilenvorschub, aus.
In Zeile 10 geben wir mit Print (ohne Zeilenvorschub) die Meldung „Mein Name ist “ aus. Wir machen das so, weil wir in der selben Zeile weitere Textausgaben anhängen möchten. Beachte das Leerzeichen am Ende des Strings – es sorgt dafür, dass die nächste Print-Ausgabe nicht direkt am letzten Wort der Meldung klebt.
Zeile 11 hängt den in der zuvor in der String-Variablen meinName$ gespeicherten String „Callimero“ an.
Zeile 12 schließt den zuvor begonnen Satz mit einem Punkt ab und gibt einen Zeilenvorschub aus.
Zeile 13 gibt den Satz „Nun ist es heraus…“ aus und führt einen weiteren Zeilenvorschub durch.
Das Programm endet mit dem Schlüsselwort End in Zeile 14.
Ein Programm mit Benutzereingabe
Bis jetzt haben wir dem Computer alles, was er „sagen“ soll, fest vorgegeben. Wie aber können wir ihm die Werte, mit denen er arbeiten soll, auch zur Laufzeit mitteilen? Nun, unter BlitzBasic gibt es dafür mehrere infrage kommende Möglichkeiten. Für die Abfrage in Shell-Programmen kommen hier die beiden Schlüsselwörter Edit$ (für Strings) und Edit (für Zahlenwerte) in Frage. Das Listing „myname2.ab3“ illustriert das. Gib es ein, speichere es und führe es aus.
; ---------------------------
; Listing: myname2.ab3
; Ein Programm mit Variablen
; Version 2.0
; ---------------------------
meinName$ = "Callimero" ; eine String-Variable deklarieren
NPrint "Hallo, Welt!"
Print "Mein Name ist "
Print meinName$
NPrint "."
NPrint "Nun ist es heraus..."
NPrint "" ; gibt eine Leerzeile aus
; -- Benutzereingabe mit Input --
Print "Wie lautet dein Name? "
deinName$ = Edit$(30)
; -- Ausgabe --
greetStr$ = "Tach auch, " + deinName$ + "!"
NPrint greetStr$
End
Ausgabe:
Hallo, Welt!
Mein Name ist Callimero.
Nun ist es heraus...
Wie lautet dein Name? Micha B.
Tach auch, Micha B.!
Programmanalyse:
Zeile 17 – Ausgabe der Aufforderung, den Namen einzugeben. Wir verwenden Print, damit die Eingabemarke nach dem folgenden Edit$-Befehl nicht in einer neuen Zeile ausgegeben wird.
In Zeile 18 weisen wir die Benutzereingabe per Edit$ der Variablen deinName$ zu. Der Syntax von Edit$ lautet Edit$([Default Text,] Eingabelänge in Zeichen)
In Zeile 21 setzen wir mit dem Pluszeichen aus mehreren Strings einen neuen String zusammen (String Concatenation). Der zusammengesetzte String wir der Stringvariablen greetStr$ zugewiesen.
Zeile 22 gibt den Inhalt der Variable greetStr$ aus.
Überprüfen von Variablen durch den Compiler
AmiBlitz3 verfügt – im Gegensatz zum alten BlitzBasic v2.1 – über die Möglichkeit, dem Compiler mitzuteilen, dass er eine strikte Syntaxprüfung vornehmen und u.a. verwendete Variablen vor ihrer Benutzung auf korrekte Verwendung überprüfen soll. Eine strikte Syntaxprüfung hat große Vorteile bei der Programmentwicklung, denn es erspart es dir von vorn herein, durch falsch genutzte Variablen und Funktionen schwer aufzuspürende Bugs in deinem Programm einzubauen. Die strikte Syntaxprüfung schaltest du mit dem compilerinternen Befehl SYNTAX am Anfang deines Quelltexts ein. Der Befehl übernimmt einen numerischen Wert für die Intensität der Prüfung:
SYNTAX 0 – Prüfung abschalten, Variablen müssen nicht vor der ersten Verwendung deklariert werden (wie BlitzBasic2)
SYNTAX 1 – Variablen müssen zwingend mit DEFTYPE deklariert werden
SYNTAX 2 – Variablen müssen bei der ersten Verwendung mit DEFTYPE deklariert werden
Es bleibt dir überlassen, ob du in deinen eigenen Programmen dieses Feature nutzen möchtest, allerdings rate ich dir dazu, wenigstens SYNTAX 2 zu verwenden. Der gute Grund: Man verliert nicht so leicht den Überblick über seine Variablen und ihren Zweck, wenn man sich von Anfang an daran gewöhnt, diese bereits am Anfang eines Programms oder wenigstens vor der ersten Verwendung zu deklarieren, anstatt sie wild während des Programmierens zu erfinden. Ich persönlich komme aus der C/C++ Welt und bin ohnehin daran gewöhnt, meinem Compiler von Anfang an mitzuteilen, welche Variable für welchen Zweck zu verwenden ist. Darum bevorzuge ich SYNTAX 1.
Ergänze unser eben geschriebenes Programm um den Eintrag SYNTAX 1 direkt nach dem einleitenden Kommentar, speichere es unter „myname3.ab3“ und führe es aus. Wie nicht anders erwartet, wartet es mit einer Fehlermeldung auf:
Mit SYNTAX 1 haben wir festgelegt, dass Variablen zwingend mit DEFTYPE deklariert werden müssen. Also tun wir das auch:
Die Compiler-Anweisung DEFTYPE (Default Type) bestimmt den Datentyp von Variablen. Der Parameter .sgibt im vorliegenden Fall an, dass es sich bei den anschließend aufgezählten Variablen um String-Variablen handelt (siehe Anhang A – Primitive Datentypen).
Der Amiga Version-String
Auf dem Amiga kann man die Versionsinformationen eines systemkonformen Programms mit dem Version-Befehl in einer Shell abfragen. Dazu muss natürlich auch ein entsprechender Version-String vorhanden sein. So definiert man ihn:
; Amiga Version String und das Compilerdatum
!version {"MyName 3.0 (\\__DATE_GER__)"}
Hier noch einmal das vollständige, geänderte Listing:
; ---------------------------
; Listing: myname3.ab3
; Ein Programm mit Variablen
; Version 3.0
; ---------------------------
SYNTAX 1
; -- Variablendeklaration mit DEFTYPE --
DEFTYPE .s meinName$, deinName$, greetStr$
; Amiga Version String und das Compilerdatum
!version {"MyName 3.0 (\\__DATE_GER__)"}
meinName$ = "Callimero" ; eine String-Variable initialisieren
NPrint "Hallo, Welt!"
Print "Mein Name ist "
Print meinName$
NPrint "."
NPrint "Nun ist es heraus..."
NPrint "" ; gibt eine Leerzeile aus
; -- Benutzereingabe mit Input --
Print "Wie lautet dein Name? "
deinName$ = Edit$(30)
; -- Ausgabe --
greetStr$ = "Tach auch, " + deinName$ + "!"
NPrint greetStr$
End
Compiliere das Programm diesmal über das Menü Compiler->Create Executable und gib als Ziel für das ausführbare Programm RAM: und als Dateinamen myname an. Öffne danach eine Shell und überprüfe die Versionsnummer:
RAM Disk:> version RAM:myname file full
MyName 3.0 (16.03.25)
Optimierte Programme erzeugen
Jeder möchte, dass sein Programm so schnell wie möglich arbeitet. AmiBlitz3 unterstützt die Optimierung von Programmen mit dem compilerinternen Schlüsselwort OPTIMIZE n. Es sollte ganz am Anfang des zu optimierenden Quellcodes stehen und nimmt einen Zahlenwert als Parameter n:
OPTIMIZE 1 – optimiert für die Motorola MC68020 CPU
OPTIMIZE 2 – verwende eine vorhanden FPU (Achtung: ein so optimiertes Programm wird auf Amigas ohne FPU abstürzen!)
OPTIMIZE 4 – schaltet den Modus für neuen Syntax (AmiBlitz3) zu
Kombinierte Optimierungsstufen lassen sich durch die Addition dieser Werte erzeugen. Beispiel:
Hinweis: Im Debug-Modus ist die Optimierung für FPU abgeschaltet.
Die Optimierung der Größe des ausführbaren Programmes kann man über das Menü Compiler->Create minimized Executable bewirken.
Zusammenfassung
Wir haben in diesem Teil des Tutorials gelernt,
was Kommentare sind und wie man sie verwendet
wie und wann man die Befehle Print und NPrint verwendet
was eine String-Variable ist
wie man mit dem Befehl Edit$ eine Benutzereingabe in einen String einliest
wie man Teilstrings zu einem neuen String zusammensetzt
wie man den Compiler dazu veranlasst, strengere Syntaxprüfung und Code-Optimierungen vorzunehmen
was der Amiga Version String ist und wie man ihn definiert
Im weiteren Verlauf des Tutorials werden wir grundsätzlich immer Variablen vor Gebrauch deklarieren und unseren lauffähigen Programmen einen Version-String mitgeben.
Ausblick
Im nächsten Teil werden wir uns etwas genauer mit Variablen, Konstanten und Datentypen befassen.
Programme müssen auf irgendeine Weise die verwendeten Daten speichern. Variablen und Konstanten bieten verschiedene Möglichkeiten, diese Daten darzustellen und zu manipulieren. In C++ dient eine Variable dazu, Informationen zu speichern. Eine Variable ist eine Stelle im Arbeitsspeicher (Hauptspeicher, RAM) des Computers, in der man einen Wert ablegen und später wieder abrufen kann.
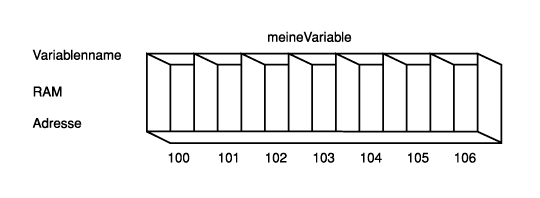
Man kann sich den Arbeitsspeicher als eine Reihe von Fächern vorstellen, die in einer langen Reihe angeordnet sind. Jedes Fach – oder Speicherstelle – ist fortlaufend nummeriert. Diese Nummern bezeichnet man als Speicheradressen oder einfach als Adressen. Eine Variable reserviert ein oder mehrere Fächer, in denen dann ein Wert abgelegt werden kann.
Der Name deiner Variablen (zum Beispiel meineVariable) ist ein Bezeichner für eines dieser Fächer, damit man es leicht finden kann, ohne dessen Speicheradresse zu kennen. Wie die folgende Abbildung zeigt, beginnt unsere Variable meineVariable an der Speicheradresse 103. Je nach Größe (= dem Datentyp) von meineVariable kann die Variable eine oder mehrere Speicheradressen belegen:
Speicher reservieren
Wenn man in C++ eine Variable definiert, muss man dem Compiler nicht nur deren Namen, sondern auch den Datentyp der Variablen mitteilen – also, ob es sich zum Beispiel um eine Ganzzahl (Integer) oder ein Zeichen (Buchstaben, Ziffern etc.) handelt. Anhand dieser Information weiß der Compiler, um welche Art Variable es sich handelt und wieviel Platz im Speicher für die Aufnahme des Wertes der Variablen zu reservieren ist.
Jedes »Fach« im Speicher ist ein Byte groß. Wenn die erzeugte Variable vier Bytes benötigt, muss man vier Bytes im Speicher – oder vier Fächer – reservieren. Der Variablentyp (zum Beispiel int für Integer) teilt dem Compiler mit, wie viele Speicherplätze (oder Fächer) für diese Variable benötigt werden.
Da Computer Werte in Bitsund Bytes darstellen und Speicher in Bytes gemessen wird, ist es wichtig, dass du diese Begriffe verstehst und verinnerlichst.
Größe von Integer-Werten
Jeder Variablentyp belegt im Speicher einen bestimmten Bereich, dessen Größe immer gleichbleibend ist, auf verschiedenen Computern aber unterschiedlich groß sein kann. Das heißt, ein Integer-Wert (Datentyp int) nimmt auf der einen Maschine zwei Bytes, auf einer anderen vielleicht vier ein – aber auf ein und demselben Computer ist dieser Platz immer gleich groß.
Eine Variable vom Typ char (zur Aufnahme von Zeichen) ist gewöhnlich ein Byte lang. Eine Ganzzahl vom Typ short belegt auf den meisten Computern zwei Bytes, eine Ganzzahl vom Typ long ist normalerweise vier Bytes lang, und eine Ganzzahl (ohne das Schlüsselwort short oder long) kann zwei oder vier Bytes einnehmen. Die Größe einer Ganzzahl wird vom Computer (16Bit oder 32Bit oder 64Bit) oder vom Compiler bestimmt. Auf einem 64-Bit-PC mit aktuellem C++ Compiler belegen die Ganzzahlen vier Bytes. Dieses Tutorial geht davon aus, dass Ganzzahlen vier Bytes groß sind. Das muss bei dir jedoch nicht so sein. Mit dem Listing „sizes.cpp“ lässt sich die genaue Größe der Typen auf Ihrem Computer bestimmen.
// Listing: sizes.cpp
#include <iostream>
using namespace std;
int main(void)
{
cout << "Groesse eines int:\t\t" << sizeof(int) << " Bytes.\n";
cout << "Groesse eines short int:\t" << sizeof(short int) << " Bytes.\n";
cout << "Groesse eines long int:\t" << sizeof(long int) << " Bytes.\n";
cout << "Groesse eines char:\t\t" << sizeof(char) << " Bytes.\n";
cout << "Groesse eines float:\t\t" << sizeof(float) << " Bytes.\n";
cout << "Groesse eines double:\t" << sizeof(double) << " Bytes.\n";
cout << "Groesse eines bool:\t\t" << sizeof(bool) << " Bytes.\n";
return 0;
}
Hinweis: Der sizeof()-Operator gibt den Speicherbedarf einer Variable oder eines Datentyps zurück.
Ausgabe:
Groesse eines int: 4 Bytes.
Groesse eines short int: 2 Bytes.
Groesse eines long int: 8 Bytes.
Groesse eines char: 1 Bytes.
Groesse eines float: 4 Bytes.
Groesse eines double: 8 Bytes.
Groesse eines bool: 1 Bytes.
Vorzeichenbehaftete Variablen: signed und unsigned
Alle genannten Typen kommen außerdem in zwei Versionen vor: mit Vorzeichen (signed ) und ohne Vorzeichen (unsigned). Dem liegt der Gedanke zugrunde, dass man manchmal zwar negative Zahlen benötigt, manchmal aber nicht. Ganze Zahlen (short und long) ohne das Wort unsigned werden als signed (das heißt: vorzeichenbehaftet) angenommen. Vorzeichenbehaftete Ganzzahlen sind entweder negativ oder positiv, während ganze Zahlen ohne Vorzeichen (unsigned int) immer positiv sind.
Da sowohl für vorzeichenbehaftete als auch vorzeichenlose Ganzzahlen dieselbe Anzahl von Bytes zur Verfügung steht, ist die größte Zahl, die man in einem unsigned int speichern kann, doppelt so groß wie die größte positive Zahl, die man in einem signed int unterbringt. Ein unsigned short int kann Zahlen von 0 bis 65535 speichern. Bei einem signed short int ist die Hälfte der Zahlen negativ. Daher kann ein signed short int Zahlen im Bereich von -32768 bis 32767 darstellen. Sollte dich dieses etwas verwirren, so findest du unter „Tabelle: Datentypen unter C/C++„ eine ausführliche Beschreibung.
Grundlegende Datentypen
In C/C++ gibt es weitere Variablentypen, die man zweckentsprechend in ganzzahlige Variablen (die bisher behandelten Typen), Fließkommavariablen und Zeichenvariablen einteilt.
Die Werte von Fließkommavariablen lassen sich als Bruchzahlen ausdrücken – das heißt, es handelt sich um reelle Zahlen.
Zeichenvariablen(char) nehmen ein einzelnes Byte auf und dienen der Speicherung der 256 möglichen Zeichen und Symbole der ASCII- und erweiterten ASCII-Zeichensätze.
Der ASCII–Zeichensatz ist ein Standard, der die im Computer verwendeten Zeichen definiert. ASCII steht als Akronym für American Standard Code for Information Interchange (amerikanischer Standard-Code für den Informationsaustausch). Nahezu jedes Computer-Betriebssystem unterstützt ASCII. Daneben sind meistens weitere internationale Zeichensätze möglich.
Die in C++-Programmen verwendeten gängigsten Variablentypen sind in der Tabelle „Variablentypen“ aufgeführt. Diese Tabelle zeigt den Variablentyp, den belegten Platz im Speicher (Grundlage ist der Computer des Autors) und den möglichen Wertebereich, der sich aus der Größe des Variablentyps ergibt. Vergleichen Sie dazu die Ausgabe des Programms aus dem Listing „sizes.cpp“.
Tabelle: Variablentypen
Typ
Größe
Wert
bool
1 Byte
true oder false
unsigned short int
2 Byte
0 bis 65,535
short int
2 Byte
-32,768 bis 32,767
unsigned long int
4 Byte
0 bis 4,294,967,295
long int
4 Byte
-2,147,483,648 bis
2,147,483,647
int (16 Bit)
2 Byte
-32,768 bis 32,767
int (32/64 Bit)
4 Byte
-2,147,483,648 bis
2,147,483,647
unsigned int (16 Bit)
2 Byte
0 bis 65,535
unsigned int (32/64 Bit)
4 Byte
0 bis 4,294,967,295
char
1 Byte
256 Zeichenwerte
float
4 Byte
1.2e-38 bis 3.4e38
double
8 Byte
2.2e-308 bis 1.8e308
Variablen definieren
Wenn du eine Variable deklarierst, wird dafür Speicherplatz allokiert (bereitgestellt). Was auch immer zu diesem Zeitpunkt sich in dem Speicherplatz befindet, stellt den Wert dieser Variablen dar. Wie du dieser Speicherposition einen neuen Wert zuweisen kannst, wirst du gleich erfahren.
Eine Variable erzeugt oder definiert man, indem man den Typ, mindestens ein Leerzeichen, den Variablennamen und ein Semikolon eintippt. Als Variablenname eignet sich nahezu jede Buchstaben-/Ziffernkombination, die allerdings keine Leerzeichen enthalten darf. Gültige Variablennamen sind zum Beispiel x, J23qrsnf und meinAlter. Gute Variablennamen sagen bereits etwas über den Verwendungszweck der Variablen aus („sprechende“ Variablennamen) und erleichtern damit das Verständnis für den Programmablauf. Die folgende Anweisung definiert eine Integer-Variable namens meinAlter:
int meinAlter;
Für die Programmierpraxis möchte ich dir nahelegen, wenig aussagekräftige Namen wie J23qrsnf zu vermeiden und kurze, aus einem Buchstaben bestehende Variablennamen (wie x oder i) auf Variablen zu beschränken, die nur kurz, für wenige Zeilen Code benötigt werden (z. B. als Zählvariable). Verwende ansonsten lieber „sprechende“ Namen wie meinAlter oder wie_viele_Katzen. Solche Namen sind leichter zu verstehen, wenn du dich drei Wochen später kopfkratzend nach dem Sinn und Zweck deines Codes fragst.
Groß-/Kleinschreibung, Umlaute und Sonderzeichen
C/C++ beachtet die Groß-/Kleinschreibung und behandelt demnach Großbuchstaben und Kleinbuchstaben als verschiedene Zeichen. Eine Variable namens alter unterscheidet sich von Alter und diese wiederum von ALTER.
Für die Schreibweise von Variablennamen gibt es mehrere Konventionen. Unabhängig davon, für welche du dich entscheidest ist es ratsam, innerhalb eines Programms bei der einmal gewählten Methode zu bleiben.
Viele Programmierer bevorzugen für Variablennamen Kleinbuchstaben. Wenn der Name aus zwei Wörtern besteht (zum Beispiel mein Auto), gibt es zwei übliche Konventionen: mein_auto oder meinAuto. Letztere Form wird auch als Kamel-Notation („CamelCase“) bezeichnet, da die Großschreibung im Wort selbst an einen Kamelhöcker erinnert.
Umlaute und bestimmte Sonderzeichen(äÄ oO üÜ ß \ /) dürfen in Variablennamen nicht vorkommen.
Ungarische Notation
Viele fortgeschrittene Programmierer schreiben Ihren Code in der sogenannten Ungarischen Notation. Dieser Notation liegt der Gedanke zugrunde, dass jede Variable mit einem oder mehreren Buchstaben beginnt, die auf den Typ der Variablen verweisen. So wird ganzzahligen Variablen (Integer) ein kleines ivorangestellt oder Variablen vom Typ long ein kleines l. Andere Notationen verweisen auf Konstanten, globale Variablen, Zeiger und so weiter. Dies ist jedoch für die C-Programmierung von wesentlich größerer Bedeutung als für C++, da C++ die Erzeugung benutzerdefinierter Datentypen unterstützt (siehe »Klassen«), und von sich aus typenstrenger ist.
Schlüsselwörter
In C++ sind bestimmte Wörter reserviert, die man nicht als Variablennamen verwenden darf. Es handelt sich dabei um die Schlüsselwörter, mit denen der Compiler das Programm steuert. Zu den Schlüsselwörtern gehören zum Beispiel if, while, for und main. Im allgemeinen fallen aussagekräftige Name für Variablen nicht mit Schlüsselwörtern zusammen. Eine Liste der C++-Schlüsselwörter findest du im „Anhang: Schlüsselwörter in C/C++„.
Mehrere Variablen gleichzeitig erzeugen
In einer Anweisung lassen sich mehrere Variablen desselben Typs gleichzeitig erzeugen, indem man den Typ schreibt und dahinter die Variablennamen durch Kommata getrennt aufführt. Dazu ein Beispiel:
unsigned int meinAlter, meinGewicht; //Zwei Variablen vom Typ unsigned int
long Flaeche, Breite, Laenge; //Drei Variablen vom Typ long
Wie man sieht, werden meinAlter und meinGewicht gemeinsam als Variablen vom Typ unsigned int deklariert. Die zweite Zeile deklariert drei eigenständige Variablen vom Typ long mit den Namen Flaeche, Breite und Laenge. Der Typ (long) wird allen Variablen zugewiesen, so dass man in ein- und derselben Definitionsanweisung keine unterschiedlichen Typen festlegen kann.
Werte an Variablen zuweisen
Einen Wert weist man einer Variablen mit Hilfe des Zuweisungsoperators (=) zu. Zum Beispiel formuliert man die Zuweisung des Wertes 5 an die Variable Breite wie folgt:
unsigned short Breite;
Breite = 5;
Diese Schritte kann man zusammenfassen und die Variable Breite bei ihrer Definition initialisieren:
unsigned short Breite = 5;
Die Initialisierung sieht nahezu wie eine Zuweisung aus, und bei Integer-Variablen gibt es auch kaum einen Unterschied. Bei der späteren Behandlung von Konstanten werden Sie sehen, das man bestimmte Werte initialisieren muss, da Zuweisungen nicht möglich sind. Der wesentliche Unterschied besteht darin, dass die Initialisierung bei der Erzeugung der Variablen stattfindet.
Ebenso wie Sie mehrere Variable gleichzeitig definieren können, ist es auch möglich, mehr als eine Variable auf einmal zu erzeugen. Betrachten wir folgendes Beispiel:
//Erzeugung von zwei long-Variablen und ihre Initialisierung
long Breite = 5, Laenge = 7;
In diesem Beispiel wird die Variable Breite vom Typ long mit 5 und die Variable Laenge vom Typ long mit dem Wert 7 initialisiert. Sie können aber auch Definitionen und Initialisierungen mischen:
int meinAlter = 39, ihrAlter, seinAlter = 40;
Das Listing „flaeche.cpp“ zeigt ein vollständiges Programm, das du sofort kompilieren kannst. Es berechnet die Fläche eines Rechtecks und schreibt das Ergebnis auf den Bildschirm:
// Listing: flaeche.cpp
// - demonstriert den Einsatz von Variablen
#include <iostream>
using namespace std;
int main(void)
{
unsigned short int Width = 5, Length;
Length = 10;
// eine Variable vom Typ 'unsigned short int' erzeugen und
// mit dem Ergebnis der Multiplikation von Width und Length
// initialisieren:
unsigned short int Area = (Width * Length);
// Werte ausgeben:
cout << "Breite: " << Width << endl;
cout << "Laenge: " << Length << endl;
cout << "Flaeche: " << Area << endl;
return 0;
}
Ausgabe:
Breite: 5
Laenge: 10
Flaeche: 50
Programmanalyse:
Zeile 3 enthält die include-Anweisung für die iostream-Bibliothek, die wir benötigen, um cout verwenden zu können. In Zeile 4 beginnt das Programm.
In Zeile 9 wird die Variable Width als vorzeichenloser short int definiert und mit dem Wert 5 initialisiert. Eine weitere Variable vom gleich Typ, Length, wird ebenfalls hier definiert, aber nicht initialisiert. In Zeile 10 erfolgt die Zuweisung des Wertes 10 an die Variable Length.
Zeile 15 definiert die Variable Area vom Typ unsigned short int und initialisiert sie mit dem Wert, der sich aus der Multiplikation von Width und Length ergibt. In den Zeilen 18 bis 20 erfolgt die Ausgabe der Variablenwerte auf dem Bildschirm. Beachte, dass das spezielle Wort endl eine neue Zeile erzeugt.
Pseudo-Datentypen mit typedef
Es ist lästig, zeitraubend und vor allem fehleranfällig, wenn man häufig unsigned short int schreiben muss. In C++ kann man einen Alias für diese Wortfolge mit Hilfe des Schlüsselwortes typedef (für Typendefinition) erzeugen.
Mit diesem Schlüsselwort erzeugt man lediglich ein Synonym und keinen neuen Typ (letzteres heben wir uns für später auf). Auf das Schlüsselwort typedef folgt ein vorhandener Typ und danach gibt man den neuen Namen an. Den Abschluss bildet ein Semikolon. Beispielsweise erzeugt
typedef unsigned short int USHORT;
den neuen Namen USHORT, den man an jeder Stelle verwenden kann, wo man sonst unsigned short int schreiben würde. Listing „typedef.cpp“ ist eine Neuauflage von Listing „flaeche.cpp“ und verwendet die Typendefinition USHORT anstelle von unsigned short int. Schauen wir uns das am praktischen Beispiel an:
// Listing: typedef.cpp
// Zeigt die Verwendung des Schlüsselworts typedef
#include <iostream>
using namespace std;
typedef unsigned short int USHORT; // mit typedef definiert
int main()
{
USHORT Width = 5;
USHORT Length;
Length = 10;
USHORT Area = Width * Length;
cout << "Breite: " << Width << "\n";
cout << "Laenge: " << Length << endl;
cout << "Flaeche: " << Area <<endl;
return 0;
}
Das Programm macht dasselbe wie sein Vorgänger flaeche.cpp – allerdings haben wir uns per typedef ein wenig Tipparbeit gespart.
Ausgabe:
Breite: 5
Laenge: 10
Flaeche: 50
Wann verwendet man short und wann long?
Neueinsteiger in die C++-Programmierung wissen oft nicht, wann man eine Variable als long und wann als short deklarieren sollte. Die Regel ist einfach: Wenn der in der Variablen zu speichernde Wert zu groß für seinen Typ werden kann, nimmt man einen größeren Typ.
Wie die Tabelle Datentypen unter C/C++ zeigt, können ganzzahlige Variablen vom Typ unsigned short (vorausgesetzt, dass sie aus 2 Bytes bestehen) nur Werte bis zu 65535 aufnehmen. Variablen vom Typ signed short verteilen ihren Wertebereich auf negative und positive Zahlen. Deshalb ist das Maximum eines solchen Typs nur halb so groß.
Obwohl Integer-Zahlen vom Typ unsigned long sehr große Ganzzahlen aufnehmen können (bis 4.294.967.295), hat auch dieser Typ einen begrenzten Wertebereich. Benötigt man größere Zahlen, kann man auf float oder double ausweichen und einen gewissen Genauigkeitsverlust in Kauf nehmen. Variablen vom Typ float oder double können zwar extrem große Zahlen speichern, allerdings sind auf den meisten Computern nur die ersten 7 bzw. 19 Ziffern signifikant. Das bedeutet, dass die Zahl nach dieser Stellenzahl mit Verlust gerundet wird. Alternativ könnte man aber auch den Datentyp unsigned long long verwenden – dieser speichert Werte zwischen 0 und 18446744073709551615.
Schlechter Tipp für Fulderer: Kürzere Variablen belegen weniger Speicher. Heute jedoch ist Speicher billig und das Leben kurz. Deshalb lassen Sie sich nicht davon abhalten, int zu verwenden, auch wenn damit 4 Byte auf Ihrem PC belegt werden.
Ein guter Tipphingegen ist es, vor der Vergabe eines Datentyps für eine Variable genau zu prüfen, wie groß eine zu speichernde Zahl tatsächlich werden könnte.
Bereichsüberschreitung bei Integer-Werten vom Typ unsigned
Die Tatsache, dass Ganzzahlen vom Typ unsigned long nur einen begrenzten Wertebereich aufnehmen können, ist nur selten ein Problem. Aber was passiert, wenn der Platz im Verlauf des Programms zu klein wird?
Wenn eine Ganzzahl vom Typ unsigned ihren Maximalwert erreicht, schlägt der Zahlenwert um und beginnt von vorn. Vergleichbar ist das mit einem Kilometerzähler. Das Listing „ueberlauf.cpp“ demonstriert den Versuch, einen zu großen Wert in einer Variablen vom Typ short int abzulegen:
// Listing: ueberlauf.cpp
// demonstriert den Überlauf einer Variablen
#include <iostream>
using namespace std;
int main(void)
{
unsigned short int smallNumber;
smallNumber = 65535;
cout << "Kleine Zahl: " << smallNumber << endl;
smallNumber++;
cout << "Kleine Zahl: " << smallNumber << endl;
smallNumber++;
cout << "Kleine Zahl: " << smallNumber << endl;
return 0;
}
Ausgabe:
Kleine Zahl: 65535
Kleine Zahl: 0
Kleine Zahl: 1
Programmanalyse:
Zeile 9 deklariert smallNumber vom Typ unsigned short int(auf dem Computer des Autors 2 Bytes für einen Wertebereich zwischen 0 und 65535). Zeile 11 weist den Maximalwert smallNumber zu und gibt ihn in Zeile 12 aus.
Die Anweisung in Zeile 13 inkrementiertsmallNumber, das heißt, addiert den Wert 1. Das Symbol für das Inkrementieren ist ++ (genau wie der Name C++ eine Inkrementierung von C symbolisieren soll). Der Wert in smallNumber sollte nun 65536 lauten. Da aber Ganzzahlen vom Typ unsigned short keine Zahlen größer als 65535 speichern können, schlägt der Wert zu 0 um. Die Ausgabe dieses Wertes findet in Zeile 14 statt.
Die Anweisung in Zeile 15 inkrementiert smallNumber erneut. Es erscheint nun der neue Wert 1.
Bereichsüberschreitung bei Integer-Werten vom Typ signed
Im Gegensatz zu unsigned Integer-Zahlen besteht bei einer Ganzzahl vom Typ signed die Hälfte des Wertebereichs aus negativen Werten. Den Vergleich mit einem Kilometerzähler stellen wir nun so an, dass er bei einem positiven Überlauf vorwärts und bei negativen Zahlen rückwärts läuft. Vom Zählerstand 0 ausgehend erscheint demnach die Entfernung ein Kilometer entweder als 1 oder -1. Wenn man den Bereich der positiven Zahlen verlässt, gelangt man zur größten negativen Zahl und zählt dann weiter herunter bis Null. das Listing „ueberlauf2.cpp“ zeigt die Ergebnisse, wenn man auf die maximale positive Zahl in einem signed short int eine 1 addiert:
// Listing: ueberlauf2.cpp
// demonstriert den Überlauf einer Variablen
#include <iostream>
using namespace std;
int main()
{
short int smallNumber;
smallNumber = 32767;
cout << "Kleine Zahl: " << smallNumber << endl;
smallNumber++;
cout << "Kleine Zahl: " << smallNumber << endl;
smallNumber++;
cout << "Kleine Zahl: " << smallNumber << endl;
return 0;
}
Ausgabe:
Kleine Zahl: 32767
Kleine Zahl: -32768
Kleine Zahl: -32767
Programmanalyse:
Zeile 9 deklariert smallNumber dieses Mal als signed short int (wenn man nicht explizit unsigned festlegt, gilt per Vorgabe signed). Das Programm läuft fast genau wie das vorherige, liefert aber eine andere Ausgabe. Um diese Ausgabe zu verstehen, muss man die Bit-Darstellung vorzeichenbehafteter (signed) Zahlen in einer Integer-Zahl von 2 Bytes Länge kennen.
Analog zu vorzeichenlosen Ganzzahlen findet bei vorzeichenbehafteten Ganzzahlen ein Umschlagen vom größten positiven Wert in den höchsten negativen Wert statt.
Zeichen
Zeichen-Variablen (vom Typ char) sind in der Regel 1 Byte groß und können damit 256 Werte aufnehmen. Eine Variable vom Typ char kann als kleine Zahl (0-255) oder als Teil des ASCII-Zeichensatzes interpretiert werden. ASCII steht für American Standard Code for Information Interchange (amerikanischer Standard-Code für den Informationsaustausch). Mit dem ASCII-Zeichensatz und seinem ISO-Gegenstück (International Standards Organization) können alle Buchstaben, Zahlen und Satzzeichen codiert werden.
Computer haben keine Ahnung von Buchstaben, Satzzeichen oder Sätzen. Alles was sie verstehen, sind Zahlen. Im Grunde genommen kann ein Computer nur feststellen, ob genügend Strom an einem bestimmten Leitungspunkt vorhanden ist. Wenn ja, wird dies intern mit einer 1 dargestellt, wenn nicht mit einer 0. Durch die Kombination von Einsen und Nullen erzeugt der Computer Muster, die als Zahlen interpretiert werden können. Und diese Zahlen können wiederum Buchstaben und Satzzeichen zugewiesen werden
Im ASCII-Code wird dem kleinen »a« der Wert 97 zugewiesen. Allen Klein- und Großbuchstaben sowie den Zahlen und Satzzeichen werden Werte zwischen 1 und 128 zugewiesen. Weitere 128 Zeichen und Symbole sind für den Computer-Hersteller reserviert. In der Realität hat sich aber der erweiterte IBM-Zeichensatz und auf modernen Rechnern der UTF-8 Zeichensatz als Quasi-Standard durchgesetzt.
Zeichen und Zahlen
Wenn du ein Zeichen, zum Beispiel »a«, in einer Variablen vom Typ char ablegst, steht dort eigentlich eine Zahl zwischen 0 und 255. Der Compiler kann Zeichen (dargestellt durch ein einfaches Anführungszeichen gefolgt von einem Buchstaben, einer Zahl oder einem Satzzeichen und einem abschließenden einfachen Anführungszeichen) problemlos in ihren zugeordneten ASCII-Wert und wieder zurück verwandeln.
Die Wert/Buchstaben-Beziehung ist zufällig. Dass dem kleinen »a« der Wert 97 zugewiesen wurde, ist reine Willkür. So lange jedoch, wie jeder (Tastatur, Compiler und Bildschirm) sich daran hält, gibt es keine Probleme. Du solltest jedoch beachten, dass zwischen dem Wert 5 und dem Zeichen »5« ein großer Unterschied besteht. Letzteres hat einen Wert von 53, so wie das »a« einen Wert von 97 hat.
Schreiben wir ein Programm, welches Zeichen anhand ihres ASCII-Codes ausdruckt (Listing „asciicode.cpp“):
// Listing: asciicode.cpp
// druckt Zeichen anhand von Zahlen
#include <iostream>
using namespace std;
int main(void)
{
for (int i = 32; i<128; i++)
cout << (char) i;
return 0;
}
Dieses einfache Programm druckt die Zeichenwerte für die Integer 32 bis 127.
Besondere Zeichen
Der C++-Compiler kennt einige spezielle Formatierungszeichen. Die Tabelle Escape-Codes listet die geläufigsten auf. In deinem Code gibst du diese Zeichen mit einem vorangestellten Backslash (auch Escape-Zeichen genannt) ein. Um zum Beispiel einen Tabulator in deinen Code mit aufzunehmen, würdest du ein einfaches Anführungszeichen, den Backslash, den Buchstaben t und ein abschließendes einfaches Anführungszeichen eingeben.
char tabZeichen = '\t';
Dies Beispiel deklariert eine Variable vom Typ char und initialisiert sie mit dem Zeichenwert \t, der als Tabulator erkannt wird. Diese speziellen Druckzeichen werden benötigt, wenn die Ausgabe entweder auf dem Bildschirm, in eine Datei oder einem anderen Ausgabegerät erfolgen soll.
Ein Escape-Zeichen ändert die Bedeutung des darauf folgenden Zeichens. So ist das Zeichen n zum Beispiel nur der Buchstabe n. Wird davor jedoch ein Escape-Zeichen gesetzt (\), steht das Ganze für eine neue Zeile.
Tabelle: Escape-Codes
Zeichen
Bedeutung
\n
Neue Zeile
\t
Tabulator
\b
Backspace
\“
Anführungszeichen
\‘
Einfaches Anführungszeichen
\?
Fragezeichen
\\
Backslash
Was ist eine Konstante?
Konstanten sind ebenso wie Variablen benannte Speicherstellen. Während sich Variablen aber ändern können, behalten Konstanten – wie der Name bereits sagt – immer ihren Wert. Du musst eine Konstante bei der Erzeugung initialisieren und kannst ihr dann später keinen neuen Wert zuweisen.
Literale Konstanten
C++ kennt zwei Arten von Konstanten: literale und symbolische.
Eine literale Konstante ist ein Wert, den man direkt in das Programm an der Stelle des Vorkommens eintippt. In der Anweisung
int meinAlter = 39;
ist meinAlter eine Variable vom Typ int, während die Zahl 39 eine literale Konstante bezeichnet. Man kann 39 keinen Wert zuweisen oder diesen Wert ändern.
Symbolische Konstanten
Eine symbolische Konstante wird genau wie eine Variable durch einen Namen repräsentiert. Allerdings lässt sich im Gegensatz zu einer Variablen der Wert einer Konstanten nicht nach deren Initialisierung ändern.
Wenn dein Programm eine Integer-Variable namens Studenten und eine weitere namens Klassen enthält, kann man die Anzahl der Studenten berechnen, wenn die Anzahl der Klassen bekannt ist und man weiß, dass 15 Studenten zu einer Klasse gehören:
Studenten = Klassen * 15;
Wenn man später die Anzahl der Stunden pro Klasse ändern möchte, braucht man das nur in der Definition der Konstanten StudentenProKlasse vorzunehmen, ohne dass man alle Stellen ändern muss, wo man diesen Wert verwendet hat.
Es gibt zwei Möglichkeiten, eine symbolische Konstante in C++ zu deklarieren. Die herkömmliche und inzwischen veraltete Methode aus dem Sprachumfang von C erfolgt mit der Präprozessor-Direktiven #define.
Konstanten mit #define definieren
Um eine Konstante auf die herkömmliche Weise zu definieren, gibt man ein:
#define StudentenProKlasse 15
Beachte, dass StudentenProKlasse keinen besonderen Typ (etwa int oder char) aufweist. #define nimmt eine einfache Textersetzung vor. Der Präprozessor schreibt an alle Stellen, wo StudentenProKlasse vorkommt, die Zeichenfolge 15 in den Quelltext.
Da der Präprozessor vor dem Compiler ausgeführt wird, kommt Ihr Compiler niemals mit der symbolischen Konstanten in Berührung, sondern bekommt immer die Zahl 15 zugeordnet.
Konstanten mit const definieren
Obwohl #define nach wie vor funktioniert, gibt es in C++ eine neue, bessere und elegantere Lösung zur Definition von Konstanten:
const unsigned short int StudentenProKlasse = 15;
Dieses Beispiel deklariert ebenfalls eine symbolische Konstante namens StudentenProKlasse , dieses Mal ist aber StudentenProKlasse als Typunsigned short int definiert. Diese Version bietet verschiedene Vorteile. Zum einen lässt sich der Code leichter warten und zum anderen werden unnötige Fehler vermieden. Der größte Unterschied ist der, dass diese Konstante einen Typ hat und der Compiler die zweckmäßige – sprich typgerechte – Verwendung der Konstanten frühzeitig prüfen kann. Es liegt auf der Hand, dass du dieser Lösung den Vorzug geben solltest.
Erinnerung:Konstanten können nicht während der Ausführung des Programms geändert werden. Wenn du gezwungen bist, die Konstante studentsPerClass zu ändern, dann musst du den Code ändern und neu kompilieren.
Aufzählungstypen (Enumeration)
Mit Hilfe von Aufzählungskonstanten (enum) können Sie neue Typen erzeugen und dann Variablen dieser Typen definieren, deren Werte auf einen bestimmten Bereich beschränkt sind. Beispielsweise kann man FARBE als Aufzählung deklarieren und dafür fünf Werte definieren: ROT, BLAU, GRUEN, WEISS und SCHWARZ.
Die Syntax für Aufzählungstypen besteht aus dem Schlüsselwort enum, gefolgt vom Typennamen, einer öffnenden geschweiften Klammer, einer durch Kommata getrennte Liste der möglichen Werte, einer schließenden geschweiften Klammern und einem Semikolon. Dazu ein Beispiel:
enum FARBE { ROT, BLAU, GRUEN, WEISS, SCHWARZ };
Diese Anweisung realisiert zwei Aufgaben:
FARBE ist der Name der Aufzählung, das heißt, ein neuer Typ.
ROT wird zu einer symbolischen Konstanten mit dem Wert 0, BLAU zu einer symbolischen Konstanten mit dem Wert 1, GRUEN zu einer symbolischen Konstanten mit dem Wert 2 usw.
Jeder Aufzählungskonstanten ist ein Integer-Wert zugeordnet. Wenn man nichts anderes festlegt, weist der Compiler der ersten Konstanten den Wert 0 zu und nummeriert die restlichen Konstanten fortlaufend durch. Jede einzelne Konstante lässt sich aber auch mit einem bestimmten Wert initialisieren, wobei die Werte der nicht initialisierten Konstanten immer um 1 höher sind als die Werte ihres Vorgängers. Schreibt man daher
erhält ROT den Wert 100, BLAU den Wert 101, GRUEN den Wert 500, WEISS den Wert 501 und SCHWARZ den Wert 700.
Damit kannst du Variablen vom Typ FARBE definieren, denen dann allerdings nur einer der Aufzählungswerte (in diesem Falle ROT, BLAU, GRUEN, WEISS oder SCHWARZ oder die Werte 100, 101, 500, 501 oder 700) zugewiesen werden kann. Du kannst Ihrer Variablen FARBE beliebige Farbwerte zuweisen, ja sogar beliebige Integer-Werte, auch wenn es keine gültige Farbe ist. Ein guter Compiler wird in einem solchen Fall jedoch eine Fehlermeldung ausgeben. Merke dir unbedingt, dass Aufzählungsvariablen vom Typ unsigned int sind und dass es sich bei Aufzählungskonstanten um Integer-Variablen handelt. Es ist jedoch von Vorteil, diesen Werten einen Namen zu geben, wenn Sie mit Farben, Wochentagen oder ähnlichen Wertesätzen arbeiten. Im Listing „enum.cpp“ findest du ein Programm, das eine Aufzählungskonstante verwendet:
// Listing: enum.cpp
// demonstriert die Verwendung von
// Aufzählungskonstanten
#include <iostream>
using namespace std;
int main(void)
{
// Variable für die Auswahl eines Wochentags deklarieren:
int auswahl;
// Aufzählung definieren:
enum Wochentage
{
Sonntag, Montag, Dienstag,
Mittwoch, Donnerstag, Freitag,
Samstag
};
// Programmtitel ausgeben:
cout << "\nWochentage" << endl;
cout << "----------" << endl;
// Benutzereingabe holen:
cout << "\nGib die Kennziffer eines Wochentags an (0 - 6): ";
cin >> auswahl;
// -- Benutzereingabe auswerten --
switch(auswahl)
{
case Sonntag:
cout << "\nDu hast den Sonntag im Sinn...";
break;
case Montag:
cout << "\nDu hast den Montag im Sinn...";
break;
case Dienstag:
cout << "\nDu hast den Dienstag im Sinn...";
break;
case Mittwoch:
cout << "\nDu hast den Mittwoch im Sinn...";
break;
case Donnerstag:
cout << "\nDu hast den Donnerstag im Sinn...";
break;
case Freitag:
cout << "\nDu hast den Freitag im Sinn...";
break;
case Samstag:
cout << "\nDu hast den Samstag im Sinn...";
break;
default:
cout << "\nFehler: Nur Ziffern 0 bis 6 erlaubt!";
break;
}
if ((auswahl == Sonntag) || (auswahl == Samstag))
cout << "\nDu bist ja schon im Wochenende!\n";
else
cout << "\nOK - nimm dir mal 'nen Tag frei!\n";
return 0;
}
Ausgabe:
bergmann@MB-Workstation:~/Projekte/Cpp-Kurs$ ./enum
Wochentage
----------
Gib die Kennziffer eines Wochentags an (0 - 6): 3
Du hast den Mittwoch im Sinn...
OK - nimm dir mal 'nen Tag frei!
Programmanalyse:
Der Anwender wird gebeten, einen Wert zwischen 0 und 6 einzugeben. Die Eingabe von z. B. »Sonntag« als Tag ist nicht möglich. Das Programm hat keine Ahnung, wie es die Buchstaben in Sonntag in einen der Aufzählungswerte übersetzen soll. Es kann jedoch die numerischen Werte, die der Anwender eingibt, mit einer oder mehreren Aufzählungskonstanten (wie in den Zeilen 15 bis 17 notiert) abgleichen. Die Verwendung von Aufzählungskonstanten verdeutlicht die Absicht des Vergleichs besser. Du hättest das Ganze natürlich auch mit Integer-Konstanten erreichen können – mehr dazu im nächsten Beispiel.
Zeile 11 deklariert eine Integer-Variable, in der die Benutzereingabe gespeichert werden soll
In den Zeilen 13 bis 18 definieren wir eine Aufzählung mit dem Namen Wochentage. Sie beinhaltet die Wochentage als symbolische Konstanten. Da keiner Konstanten explizit ein Wert zugewiesen wurde, beginnt die Aufzählung mit Sonntag = 0 und endet mit Samstag = 6.
Die Zeilen 25 und 26 dienen der Benutzereingabe: Zeile 25 fordert per cout zur Eingabe auf und Zeile 26 weist die Eingabe per cin der Variablen auswahl zu.
Ab Zeile 29 werten wir die Benutzereingabe aus und reagieren darauf. Dazu bedienen wir uns zunächst der Verzweigung mittels switch – case – break. Der switch-Anweisung folgt, in geschweifte Klammern gepackt, ein Anweisungsblock. Er besteht aus mehreren case-Anweisungen, die mittels einer break-Anweisung abgeschlossen werden. Zwischen case und break notiert man weitere auszuführende Anweisungen – in unserem Fall die Ausgabe des gewählten Wochentags.
In Zeile 52 wird eine default-Aktion für switch angegeben. Sie wird ausgeführt, wenn der Benutzer eine Zahl (oder gar ein Zeichen) eingibt, die nicht durch die Fallunterscheidungen der einzelnen case-Anweisungen abgedeckt wird. In unserem vorliegenden Fall gibt default eine Fehlermeldung aus. Die switch-Anweisung eignet sich besonders gut, um auf bestimmte, einzelne Werte zu reagieren.Die switch-Anweisung wertet die symbolischen Konstanten Sonntag (0) bis Samstag (6) aus, indem sie deren hinterlegte numerische Werte für Vergleiche heranzieht.
Ab Zeile 57 benutzen wir eine if – elseVerzweigung, um dem Benutzer, je nach seiner getroffenen Auswahl, noch eine kleine Meldung zukommen zu lassen. Das Schema dieses Instruments zu Fallunterscheidung sieht wie folgt aus:
if (1. Bedingung || 2. Bedingung) // WENN Bedingung 1 ODER Bedingung 2 zutrifft, dann
gib Meldung 1 aus
else // ANDERNFALLS...
gib Meldung 2 aus
Zeile 57 prüft die erste Bedingung: Hat die Variable auswahl den Wert 0 (Sonntag) ODER 6 (Samstag)? Falls Bedingung 1 zutrifft, dann wird in Zeile 58 die Meldung „Du bist ja schon im Wochenende!“ ausgegeben und die Verzweigung wird verlassen. Der else-Zweig wird dabei übersprungen, da die Bedingung ja bereits erfüllt ist. Andernfalls geht es weiter in Zeile 59.
Zeile 59: Der else-Zweig prüft, ob Bedingung 1 nicht erfüllt wurde (weder Sonntag, noch Samstag gewählt). Trifft das zu, so wird in Zeile 60 die Meldung „OK – nimm dir mal ’nen Tag frei!“ ausgegeben.Die if-Anweisung eignet sich gut, wenn mehrere Bedingungen miteinander kombiniert werden müssen. Die Bedingungen können dabei mittels bool’scher Operatoren miteinander verknüpft werden. Die Zeichenfolge „||“ steht in C/C++ für das logische ODER.
Das Programm prüft zuerst per switch-Anweisung, ob ein gültiger Wert eingegeben wurde und arbeitet danach die verknüpften Bedingungen der if-Anweisung ab. Beide Programmsegmente liefern auf jeden Fall eine Meldung.
Auch bei Eingabe einer nicht erlaubten Ziffer ändert sich daran nichts. Das Programm gibt dann zwar eine (gewollte) Fehlermeldung aus, bietet dir aber trotzdem einen Urlaubstag an. 😉
Ich hatte ja eingangs schon erwähnt, dass man das Programm, anstatt eine Aufzählung zu verwenden, auch mit einfachen Integer-Konstanten umsetzen könnte. Das Listing „intchoice.cpp“ zeigt dir in einer abgespeckten Version, wie das funktioniert:
// Listing: intchoice.cpp
// demonstriert die Verwendung von
// Integer-Konstanten
#include <iostream>
using namespace std;
int main(void)
{
// Variable für die Auswahl eines Wochentags deklarieren:
int auswahl;
// Integer-Konstanten für Wochentage definieren:
const int Sonntag = 0;
const int Montag = 1;
const int Dienstag = 2;
const int Mittwoch = 3;
const int Donnerstag = 4;
const int Freitag = 5;
const int Samstag = 6;
// Benutzereingabe holen:
cout << "\nGib die Kennziffer eines Wochentags an (0 - 6): ";
cin >> auswahl;
// äußere Schleife: Fehleingaben abfangen
if ((auswahl > -1) && (auswahl < 7))
// innere Schleife: Eingabe auswerten
if ((auswahl == Sonntag) || (auswahl == Samstag))
cout << "\nDu bist ja schon im Wochenende!\n";
else
cout << "\nOK - nimm dir mal 'nen Tag frei!\n";
else
cout << "Fehler: nur 0 bis 6 erlaubt!" << endl;
return 0;
}
Ausgabe:
# 1. Programmlauf: Ungültige Eingabe
bergmann@MB-Workstation:~/Projekte/Cpp-Kurs$ ./intchoice
Gib die Kennziffer eines Wochentags an (0 - 6): 8
Fehler: nur 0 bis 6 erlaubt!
# 2. Programmlauf: Tag 3 gewählt
bergmann@MB-Workstation:~/Projekte/Cpp-Kurs$ ./intchoice
Gib die Kennziffer eines Wochentags an (0 - 6): 3
OK - nimm dir mal 'nen Tag frei!
Programmanalyse:
In diesem Programm wurde jede Konstante (Sonntag, Montag etc.) einzeln definiert, ein Aufzählungstyp Tage existiert hier nicht. Aufzählungskonstanten haben allerdings den Vorteil, dass sie selbsterklärend sind – die Absicht des Aufzählungstyps Tage ist jedem sofort klar.
Anstatt einen Aufzählungstyp zu verwenden, definieren wir hier in den Zeilen 13 bis 19 einzelne Integer-Konstanten und weisen ihnen einen entsprechenden Wert zu.
Die Zeilen 22 und 23 dienen der Benutzereingabe mittels cout und cin.
Zeile 23: Der Variablen auswahl wird per cin der eingelesene Wert übergeben.
In Zeile 25 beginnt die äußereif-else Schleife – sie dient zum Abfangen unzulässiger Zifferneingaben und endet in Zeile 33. Die Bedingung lauten dieses Mal: WENN auswahl GRÖSSER als -1 UND auswahl KLEINER als 7... (die Zeichenfolge „&&“ steht für das logischen UND in C/C++)
Falls die Bedingung nicht zutrifft (Eingabe einer nicht erlaubten Ziffer), dann wird das Programm beim else in Zeile 32 fortgesetzt und gibt in Zeile 33 eine Fehlermeldung aus. Die äußere if-Schleife ist damit abgeschlossen und das Programm endet in Zeile 35.
Trifft die Bedingung zu, so wird die innere if-Schleife ab Zeile 28 abgearbeitet. Sie prüft, ob einer der Werte für Sonntag oder Samstag vorliegt, verzweigt entsprechend (zu Zeile 29 oder Zeile 31) und endet dann. Somit kann dann auch die äußere if-Schleife geschlossen werden, da alle Bedingungen abgearbeitet sind. Auch in diesem Fall endet das Programm anschließend mit Zeile 35.
Das Beispiel demonstriert auch den Umstand, dass if-else Schleifen ineinander verschachtelt werden können. In diesem Fall wird zunächst die äußere Schleife verarbeitet/ausgewertet und erst danach die Innere.
Zusammenfassung
In diesem Kapitel hast du Variablen und Konstanten für numerische Werte und Zeichen kennengelernt, in denen du in C/C++ während der Ausführung deines Programms Daten speichern kannst. Numerische Variablen sind entweder Ganzzahlen (char, short und long int) oder Fließkommazahlen (float und double). Die Zahlen können darüber hinaus vorzeichenlos oder vorzeichenbehaftet (unsigned und signed) sein. Wenn auch alle Typen auf unterschiedlichen Computersystemen unterschiedlich groß sein können, so wird jedoch mit dem Typ für einen bestimmte Computertyp immer eine genaue Größe angegeben.
Bevor man eine Variable verwenden kann, muss man sie deklarieren. Damit legt man gleichzeitig auch den Datentyp fest, der sich in der Variablen speichern lässt. Wenn man eine zu große Zahl in einer Integer-Variablen ablegt, erhält man ein falsches Ergebnis.
Dieses Kapitel hat auch literale und symbolische Konstanten, sowie Aufzählungskonstanten behandelt und die beiden Möglichkeiten zur Deklaration symbolischer Konstanten aufgezeigt: Die Verwendung von #define und des Schlüsselwortes const.
Texte an der Konsole ausgeben mit dem Ausgabeobjekt cout
Vorläufig werden wir cout einfach verwenden, ohne seine Funktionsweise vollständig zu verstehen. Um einen Wert auf dem Bildschirm auszugeben, musst du cout eingeben, gefolgt von dem Umleitungsoperator (<<), den man durch zweimaliges Betätigen der [<]-Taste erzeugt. Auch wenn es sich hier um zwei Zeichen handelt, werden sie von C++ als ein Symbol interpretiert. Im Anschluss an den Umleitungsoperator gibst du deine auszugebenden Daten ein. Das folgende Listing soll dir die Anwendung demonstrieren. Gib das folgende Beispiel wortgetreu ein, nur das du anstatt des Namens Micha B. deine eigenen Namen eintippst (es sei denn, du bist ich).
// Listing 'coutdemo.cpp' zeigt die Verwendung von cout
#include <iostream>
using namespace std;
int main()
{
cout << "Hallo dort.\n";
cout << "Hier ist 5: " << 5 << "\n";
cout << "Der Manipulator endl beginnt eine neue Zeile.";
cout <<
endl;
cout << "Hier ist eine große Zahl:\t" << 70000 << endl;
cout << "Hier ist die Summe von 8 und 5:\t" << 8+5 << endl;
cout << "Hier ist ein Bruch:\t\t" << (float) 5/8 << endl;
cout << "Und eine riesengroße Zahl:\t";
cout << (double) 7000 * 7000 <<
endl;
cout << "Vergiss nicht, Micha B. durch deinen Namen"
" zu ersetzen...\n";
cout << "Micha B. ist ein C++-Programmierer!\n";
return 0;
}
Ausgabe:
./coutdemo
Hallo dort.
Hier ist 5: 5
Der Manipulator endl beginnt eine neue Zeile.
Hier ist eine große Zahl: 70000
Hier ist die Summe von 8 und 5: 13
Hier ist ein Bruch: 0.625
Und eine riesengroße Zahl: 4.9e+07
Vergiss nicht, Micha B. durch deinen Namen zu ersetzen...
Micha B. ist ein C++-Programmierer!
Erklärungen:
Zeile 1 enthält einen einzeiligen Kommentar, welcher den Zweck des Programms erklärt.
Zeile 2 bindet mit der Anweisung #include<iostream> die Datei IOSTREAM in die Quellcode-Datei ein. Dies ist erforderlich, um cout und die verwandten Funktionen verwenden zu können.
Zeile 4 legt den Namensraumstd fest, in welchem cout definiert ist. Würdest du diese Anweisung weglassen, dann müsstest du im Quelltext die Anweisung um std::cout erweitern, anstatt einfach nur cout zu schreiben.
Zeile 8 gibt einen Text und einen Zeilenvorschub mittels \n (newline) aus.
In Zeile 9 werden cout drei Werte übergeben, wobei die Werte voneinander durch einen Umleitungsoperator getrennt werden. Der erste Wert ist der String „Hier ist 5:“ Beachte das Leerzeichen nach dem Doppelpunkt. Dieser Raum ist Teil des Strings. Anschließend wird dem Umleitungsoperator der Wert 5 und das Zeichen für „Neue Zeile“ ( „\n“ für newline, immer in doppelten oder einfachen Anführungszeichen) übergeben. Damit wird insgesamt folgende Zeile
Hier ist 5: 5
auf dem Bildschirm ausgegeben. Da hinter dem ersten String kein „Neue Zeile“-Zeichen kommt, wird der nächste Wert direkt dahinter ausgegeben. Dies nennt man auch »die zwei Werte verketten« (Konkatenation).
Zeile 10 gibt eine Meldung aus und in Zeile 11 wird dann dann der Manipulator endlverwendet. Sinn und Zweck von endl ist es, eine neue Zeile auf dem Bildschirm auszugeben. Damit bewirkt dieser Manipulator dasselbe, als wenn du \n(newline) verwendet hättest – endl steht für end line (Ende der Zeile).
Zeile 14 führt ein neues Formatierungszeichen, das \t, ein. Damit wird ein Tabulatorschritt eingefügt, mit dem die Ausgaben der Zeilen 14 bis 17 bündig ausgerichtet werden. Zeile 14 zeigt auch, dass nicht nur der DatentypInteger, sondern auch Integer vom Typ long ausgegeben werden können. Zeile 15 zeigt, dass cout auch einfache Additionen verarbeiten kann. Der Wert 8+5 wird an cout weitergeleitet und dann als 13 ausgegeben.
In Zeile 16 wird cout der Wert 5/8 übergeben. Mit dem Begriff (float) teilen Sie cout mit, dass das Ergebnis als Dezimalzahl ausgewertet und ausgegeben werden soll. In Zeile 18 übernimmt cout den Wert 7000 * 7000. Der Begriff (double) teilt cout mit, dass du diese Ausgabe in wissenschaftlicher Notation wünschst. Diese Themen werden wir noch im Detail im Kapitel »Variablen und Konstanten« im Zusammenhang mit den Datentypen besprechen.
In Zeile 23 hast du meinen mit deinem Namen ersetzt und der Computer nennt dich einen C++-Programmierer. 😉
Anmerkung:Über den Sinn und Zweck von Kommentaren haben wir ja bereits gesprochen. Kommentare, die beschreiben, was eh schon jeder sieht, sind nicht besonders sinnvoll. Sie können sogar kontraproduktiv sein, wenn sich der Code ändert und der Programmierer vergißt, den Kommentar mit zu ändern. Aber was für den einen offensichtlich ist, ist für andere undurchsichtig. Deshalb ist sorgfältiges Abwägen gefragt.
Zu guter Letzt möchte ich noch anmerken, dass Kommentare nicht mitteilen sollten, was du machst, sondern warum du es machst.
Programme sind besser lesbar und auch nach langer Zeit noch nachvollziehbar, wenn du den Quellcode sinnvoll kommentierst. Außerdem kann es bei der Entwicklung umfangreicherer Programme manchmal sinnvoll bei der Fehlersuche sein, bestimmte Bereiche vorübergehend auszukommentieren. Das funktioniert, weil der Compiler Kommentare bei der Übersetzung eines Programms schlichtweg überliest und deren Inhalt ignoriert. C++ kennt zwei Arten von Kommentaren, die beide ihren Anwendungsbereich und ihre Vorteile haben.
’Oldstyle’ C Kommentare
Es gibt sie schon seit den Zeiten der Programmiersprache C. Man bezeichnet sie auch als mehrzeilige Kommentare, weil alles, was zwischen der einleitenden Zeichenkombination /* und der abschließenden Zeichenkombination */ steht, vom Compiler ignoriert wird. Trotzdem können sie auch als einzeilige Kommentare verwendet werden, wenn beide Kombinationen auf der gleichen Zeile zur Anwendung kommen. Beispiele:
/*
Ich bin ein mehrzeiliger Kommentar im 'alten' Stil von ANSI C.
Der Compiler ignoriert mein Geschwätz.
*/
/* Ich bin ein mehrzeiliger Kommentar, der wie ein Einzeiliger tut. */
’Newstyle’ C++ Kommentare
Sie sind einzeilig und typisch für C++. Alles, was innerhalb der selben Zeile hinter der Zeichenkombination // steht, wird vom Compiler ignoriert. Typische Anwendungsfälle sind Beschreibungen hinter einer Anweisung oder das Auskommentieren einzelner Zeilen. Beispiele:
// ich bin ein einzeiliger Kommentar! Der Compiler ignoriert mein Geschwätz.
int i = 42 // Deklaration einer Integer-Variablen
// 'z' wird auskommentiert:
// int z = 4711;
Das Verschachteln von Kommentaren ist in C und C++ verboten:
/*
Alle meine Entchen!
/* Verboten: Ein verschachtelter Kommentar innerhalb eines Kommentars */
*/
Anmerkung:Kommentare, die beschreiben, was eh schon jeder sieht, sind nicht besonders sinnvoll. Sie können sogar kontraproduktiv sein, wenn sich der Code ändert und der Programmierer vergisst, den Kommentar mit zu ändern. Aber was für den einen offensichtlich ist, ist für andere undurchsichtig. Deshalb ist sorgfältiges Abwägen gefragt.
Zu guter Letzt möchte ich noch anmerken, dass Kommentare nicht mitteilen sollten, was du machst, sondern warum du es machst.
Quelltext-Regeln und Formatierung
C++ ist eine formatfreie Sprache. Das bedeutet, dass du bei der optischen Gestaltung deiner Quelltexte mit wenigen Einschränkungen völlig frei bist. Nehmen wir einmal an, du hättest unser erstes Programm auf diese Art notiert:
#include
<iostream>
int
main() {
std::cout << "Hallo vom langweiligsten Programm der Welt!"
<< std::endl;
return 0;
}
Unübersichtlich, nicht wahr? Trotzdem ist der Quellcode aus Compilersicht legal und wird auch anstandslos übersetzt. Ob diese Art der Formatierung für das menschliche Auge angenehm und leicht lesbar ist, bedarf vermutlich keiner Diskussion.
Es existieren viele unterschiedliche Stile und Empfehlungen bezüglich der Quellcodeformatierung. Grundsätzlich sollte der Quellcode auf jeden Fall leicht lesbar und auf eine nachvollziehbare Strukturierung aufgebaut sein. Wenn du erst einmal einen persönlichen Stil entwickelt hast, der diesen Anforderungen gerecht wird – behalte ihn möglichst konsequent bei. Es wird dir auch nach Jahren noch das Verständnis für deinen Code enorm erleichtern. Hier einige Tipps:
Rücke zusammengehörige Anweisungsblöcke und Bedingungsabfragen immer ihrer Logik nach ein. Schreibe dazu zusammengehörige Klammern stets untereinander und verwende Tabulatorsprünge, um deren Inhalte sichtbar als zugehörig zu kennzeichnen.
Verwende Leerzeilen zwischen Funktionen und thematisch abgeschlossenen Bereichen.
Achte auf die Zeilenlänge deiner Anweisungen – was auf einem hochauflösenden Monitor noch gut aussieht, kann auf dem Drucker ein Desaster sein. Beschränke dich auf bummelig 90 Zeichen pro Zeile und brich längere Zeilen unter Berücksichtigung syntaktischer Regeln um (siehe ‚Zeilenfortsetzung‘ im Abschnitt über den Syntax von C++).
Verwende, wo immer nötig, Kommentare, um dein Programm nachvollziehbar zu halten. Ein Beispiel:
/*
* Das Einsteigerseminar C++
*
* hallo2.cpp
* Das wohl langweiligste Programm der Welt, Version 2
*/
#include <iostream> // Ein-/Ausgabebibliothek einbinden
using namespace std; // Namensraum 'std' (Standard) einbinden
int main()
{
// Lange Zeichenkette aufteilen mit '\':
cout << "Das langweiligste Programm der Welt " \
"meldet sich zurueck mit einer sehr, " \
"sehr langen Zeichenkette!\n"
<< endl;
// Zwei Zeichenketten nacheinander über zwei Zeilen ausgeben:
cout << "Was ich noch sagen wollte:"
<< endl
<< "C++ macht Laune."
<< endl;
return 10; // Gib den Wert 10 zurück an den Aufrufer
}
Syntax-Regeln für die Sprache C/C++
Die Programmiersprache C/C++ beinhaltet gleich mehrere Sprachen/ Syntaxen:
C-Syntax
Präprozessor-Syntax
Printf/Scanf Formatstring Syntax
Terminal Emulation
Compiler/Linker Anweisungen
In diesem Kapitel sollen zunächst nur allgemeine Eigenschaften der Sprache, der grundlegende Syntax und die Kontrollstrukturen erklärt werden. Bei vielen Erklärungen sind Code-Beispiele vorhanden. Vieles, was du hier zu lesen bekommst, wirst du erst im weiteren Verlauf des Tutorials vollständig verstehen – trotzdem ist es wichtig, von den einzelnen Begrifflichkeiten mal gehört zu haben.
Da man aus Fehlern am meisten lernt, sind zum Teil auch negative Beispiele enthalten. Für ein besseres Verständnis empfiehlt es sich, Code-Beispiele selbst nachzuvollziehen.
Zeichensatz:
Der Syntax von C nutzt die unteren 128 Zeichen des ASCII Zeichensatzes. Da UTF-8 in den ersten 128 Zeichen deckungsgleich zu ASCII ist, kann auch dieser zur Erstellung des Source Codes genutzt werden. Zeichen außerhalb dieses gültigen Zeichensatzes können folglich nur in Strings oder Kommentaren vorkommen. Tatsächlich empfiehlt sich die Verwendung eines auf UTF-8 kodierten Zeichensatzes, da dieser bei der Übernahme eines Quelltexts zwischen verschiedenen Betriebssystemen kaum Probleme aufwirft.
Namenskonventionen
Folgende Regeln gelten bzgl. der Benennung von Variablen und Funktionen:
Variablen und Funktionsnamen können aus Buchstaben, Zahlen und dem Unterstrich bestehen. Sie müssen mit einem Buchstaben oder einem Unterstrich beginnen
C/C++ ist Case sensitiv, d.h. es wird zwischen Groß- und Kleinbuchstaben unterschieden
Schlüsselwörter können nicht für Variablen/Funktionsnamen/Datentypen genutzt werden Namenskonventionen von Library-Funktionen:
In C (und C++) sind Schlüsselwörter und Standardlibrary-Funktionen zumeist in Kleinbuchstaben geschrieben. In der C-Standardlibrary werden oftmals verkürzte Ausdrücke wie z.B. isalnum() (zum Testen ob ein Zeichen ein Buchstaben oder ein Digit ist) und in C++ der Unterstrich als Worttrenner (z.b. out_of_range) genutzt.
Makros werden per Konvention in GROSSBUCHSTABEN und ggf. mit Unterstrich als Worttrenner geschrieben.
Namen beginnend mit doppelten Unterstrich oder beginnend mit einem Unterstrich gefolgt von einem Großbuchstaben (z.B. __LINE__ _Reserved) sind für den Compiler und der Standard-C-Library vorbehalten und sollten im eigenen Programm nicht benutzt werden.
Zeilenfortsetzung
Mit dem Backslash Operator (gefolgt von einem Zeilenende) kann eine Zeile in der nächsten Zeile fortgesetzt werden. Der Compiler löscht das \-Zeichen mit anschließendem Zeilenende und ersetzt dies durch nichts. Dies ist insbesondere bei Anweisungen notwendig, die am Ende der Zeile abgeschlossen sein müssen (z.B. Strings, Makros).
Beispiele:
char str1[]="Strings müssen am Ende per Anführungszeichen abgeschlossen sein
so dass dies ein Fehler ist";
char str2[]="Dies\
ist ein Test"; //Vorsicht, führende Leerzeichen vor 'ist'
//bleiben erhalten!
/*mehrzeiliges Makro*/
#define MAX(a,b) (a>b?\
b: \
a)
//Dies ist ein Zeilenkommentar \
welcher in dieser Zeile fortgesetzt wird
/\
* dies ist ein Blockkommentar*\
/
//hinter der Zeilenfortsetzung darf nur ein CR/LF folgen
#define MAX2(a,b) \ //so dass hier kein Kommentar folgen darf
a>b?a:b
Hinweis:
Innerhalb von Char-Literatoren und Strings wird ‚\‘ als Escape-Operator genutzt, welche das ‚\‘ und ein oder mehrere folgende Zeichen ersetzt. Daher darf hinter Backslash als Zeilenfortsetzungszeichen kein weiteres Zeichen folgen.
Gültigkeit und Sichtbarkeit von Variablen
Vorrangig in der objektorientierten Programmierung werden mit Namensräumen Objekte und deren Methoden/Attribute in einer Art Baumstrukturstrukturiert. Dies ermöglicht eine eindeutige Ansprache von Variablen/Objekte, aber auch eine doppelte Verwendung von Methoden-/Attributnamen in unterschiedlichen Namensräumen. Ergänzend zu den Namensräumen kann mit public/private/proteced eine Zugriffsbeschränkung von Methoden/Attributen definiert werden.
Die Programmiersprache Cunterstützt keinen Namensraum. Zugriffsmodifikatoren werden indirekt über Header-Dateien getätigt. Hinsichtlich der Gültigkeit/Sichtbarkeit unterscheidet C folgende Bereiche:
Funktionen (Function Scope)
Datei (File Scope)
Block (Block Scope)
Funktionsparameter in Prototypen (Function Prototype Scope)
Innerhalb eines Gültigkeitsbereiches dürfen Variablen-/Funktions-/Datentypnamen nicht doppelt genutzt werden. In der Programmiersprache C++ sind weitere Scope wie z.B. Class Scope, Enumationation Scope und ergänzend das Konzept von Namensräumen vorhanden (Beschreibung folgt).
Funktionsweite Sichtbarkeit
Eine Label-Definition (als Sprungmarke für die goto-Anweisungen) erfolgt immer mit funktionsweiter Sichtbarkeit/Gültigkeit.
Dateiweite Sichtbarkeit
Erfolgt eine Funktion-/Variablen-/Datentyp-Definition außerhalb eines Block-Scopes oder von Funktionsparameter, so sind diese innerhalb der gesamten Datei und bei Funktionen/Variablen ergänzend Projektweit (für alle Objektdateien) sichtbar/gültig (= global). Alle globalen Funktionen/Variablen können von allen Dateien aus genutzt/zugegriffen werden (sofern sie zuvor deklariert wurden). Beispiel 1:
// Deklaration von func(),
// welche in Datei2.c definiert wird
extern void func(void);
// Definition der Variablen global
int global=0;
int main(void)
{
func();
global++;
return 0;
}
Beispiel 2:
// Deklaration von global,
// welche in Datei1.c definiert wird
extern int global;
// Definition der Funktion func()
void func(void)
{
global++;
}
Wird das Schlüsselwort ’static‘ der Variablen/Funktionsdefinition vorangestellt, so wird die Sichtbarkeit/Gültigkeit auf Dateiweit eingeschränkt. Variablen/Funktionen können nur innerhalb der (Objekt-) Datei genutzt werden und sind für anderen (Objekt-)Dateien unsichtbar.
Beispiel 1:
// Dateiweite Sichtbarkeit von var1
static int var1;
int main(void)
{
var1++;
return 0;
}
Beispiel 2:
// Dateiweite Sichtbarkeit von var1
static int var1;
void func(void)
{
static int var2; // Vorsicht, static
// hat hier eine andere Bedeutung
var1++;
}
Projektweite Gültigkeit
bedeutet insbesondere, dass keine doppelten Benennung von Variablen/Funktionen/Datentypen innerhalb des gesamten Projektes erlaubt sind, d.h. dass alle Variablen/Funktionennamen über alle Dateien/Librarys eindeutig sein müssen. Beispiel 1:
Datei 1:
// datei_1.cpp
#include <stdio.h>
int a=1;
int main(int argc,char *argv[])
{
printf("Hello World %d",a);
void dummy(void); //Deklaration von Dummy
dummy();
return 0;
}
Datei 2:
// datei_2.cpp
#include <stdio.h>
int a=7;
void dummy(void)
{
printf("Hello Again %d\n",a);
}
Versuche, die beiden Dateien zusammen zu compilieren:
g++ -Wall datei_1.cpp datei_2.cpp -o beipiel1
Der Linker meldet beim Zusammenfügen der Objekt-Dateien, dass die Variable a bereits woanders definiert sei (multiple definition of ‚a‘):
gcc -Wall datei1.cpp -o beispiel1
datei_1.cpp:4:5: Fehler: Redefinition von »int a«
4 | int a=1;
| ^
In Datei, eingebunden von datei_1.cpp:3:
datei_2.cpp:3:5: Anmerkung: »int a« wurde bereits hier definiert
3 | int a=7;
| ^
Hier meldet der Compiler eine Fehlermeldung, da das Symbol printf zum einen als Variable und zum anderen als Funktion (innerhalb der inkludierten Datei stdio.h beschrieben) genutzt wird (‚printf‘ redeclared as different kind of symbol):
g++ -Wall beispiel2.cpp
beispiel2.cpp:2:5: Fehler: »int printf« als andere Symbolart redeklariert
2 | int printf=7;
| ^~~~~~
In Datei, eingebunden von beispiel2.cpp:1:
/usr/include/stdio.h:356:12: Anmerkung: vorherige Deklaration von »int printf(const char*, ...)«
356 | extern int printf (const char *__restrict __format, ...);
| ^~~~~~
beispiel2.cpp: In Funktion »int main()«:
beispiel2.cpp:5:12: Warnung: Format »%d« erwartet Argumenttyp »int«, aber Argument 2 hat Typ »int (*)(const char*, ...)« [-Wformat=]
5 | printf("%d\n", printf);
| ~^ ~~~~~~
| | |
| int int (*)(const char*, ...)
Blockweite Sichtbarkeit
Erfolgt eine Funktion-/Variablen-/Datentyp Definition innerhalb einer Funktion, als Funktionsparameter oder eines Blockes, so sind diese nur innerhalb des Blockes sichtbar/gültig (= Lokale Variable). Blöcke können verschachtelt sein, so dass das bei identischer Namensgebung innere Definitionen Vorrang haben. Ebenso haben Blockdefinitionen Vorrang vor Datei-/Projektdefinitionen (überdecken diese):
blockweit1.cpp
int main(void)
{
int var2; //var2 ist nur innerhalb
//von main() sichtbar
struct xyz //Datentyp ist nur innerhalb
{int x,y,z;};//von main()
//sichtbar/gültig
extern void func(void); //Deklaration
//ist nur innerhalb von
//main() sichtbar/gültig
func();
}
void foo(void) {
struct xyz var_xyz; //Fehler, da
//Datentypedefinition hier nicht mehr
//gültig ist!
func(); //Fehler, da Deklaration
//hier nicht mehr gültig ist
}
blockweit2.cpp
#include <stdio.h>
void func(void)
{
int var2=1; //var2 ist
//nur innerhalb von
//func() sichtbar
{
int var2=2;
//var2 ist nur innerhalb
//dieses Blockes sichtbar
printf("%d\n",var2);
}
printf("%d\n",var2);
}
Auch dieses aus zwei Dateien bestehende Programm wird vom Compiler angemeckert:
g++ -Wall blockweit1.cpp blockweit2.cpp -o blockweit
blockweit1.cpp: In Funktion »int main()«:
blockweit1.cpp:2:7: Warnung: Variable »var2« wird nicht verwendet [-Wunused-variable]
2 | int var2; //var2 ist nur innerhalb
| ^~~~
blockweit1.cpp: In Funktion »void foo()«:
blockweit1.cpp:14:13: Fehler: Aggregat »foo()::xyz var_xyz« hat unvollständigen Typ und kann nicht definiert werden
14 | struct xyz var_xyz; //Fehler, da
| ^~~~~~~
blockweit1.cpp:18:2: Fehler: »func« wurde in diesem Gültigkeitsbereich nicht definiert
18 | func(); //Fehler, da Deklaration
| ^~~~
Soviel zunächst zu Syntaxregeln in C/C++. Gräme dich nicht, wenn du gerade an ‚Bahnhof‘ und ‚Züge‘ denkst – wir werden im weiteren Verlauf des Tutorials an den jeweiligen Stellen wiederholend am praktischen Beispiel auf die Syntaxregeln eingehen.
In diesem Teil des C++ Tutorials beschäftigen wir uns mit Techniken zur Speicherung unserer Quelltexte und dem Schreiben und Übersetzen derselben. Bevor es richtig losgeht, noch einige Vorüberlegungen zur Organisation der anfallenden Daten:
Betrachte ab sofort jedes Programm, das du eingibst, als eigenständiges Projekt. Lege dir zu diesem Zweck zunächst ein Sammelverzeichnis an, in welchem du dann wiederum Ordner für die eigentlichen Projekte erstellst. Beispiel:D:\Einsteigerseminar
Jedes Projekt erhält seinen eigenen Ordner, in dem alle relevanten Daten zum Projekt gespeichert werden. Dies ist das Arbeitsverzeichnis des jeweiligen Projekts! Beispiel 1:D:\Einsteigerseminar\001_Hallo Beispiel 2:D:\Einsteigerseminar\002_Kommentare
Relevante Daten können z. B. sein:
C++-Quelltext für das eigentliche Programm (Suffix: .cpp)
C++-Quelltexte, die vom Hauptprogramm eingebunden werden, um weitere Fähigkeiten zum Programm hinzu zu fügen – sog. „Header-Dateien“ (Suffix: .hpp)
Makefiles (Dateien mit Compileranweisungen zur Übersetzung des Programms, kein Suffix)
Vom Programm zu speichernde oder zu lesende Datendateien (Suffix: frei wählbar)
Grafiken (Suffix: .png | .jpg | .ico, usw …)
Textdatei mit einer Beschreibung des Programmes und/oder einer TODO-Liste (Suffix: .txt)
Für unser erstes Projekt könnte das dann z. B. so aussehen:
Erstelle zunächst in deinem Sammelverzeichnis für Projekte den Unterordner 001_Hallo. Starte dann den Editor (Geany) und speichere das (noch leere) Programm unter dem Namen hallo.cpp in diesem Ordner ab. Gib danach den folgenden Quellcode (ohne Zeilennummern!) ein und achte darauf, alles so abzutippen, wie ich es hier notiert habe:
/*
C++ Einsteiger Tutorial
Source: hallo.cpp
*/
#include <iostream>
int main()
{
std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl;
return 0;
}
Drücke nun die Funktionstaste , um das Programm zu compilieren. Wenn du alles richtig gemacht hast, meldet der Compiler:
Falls jedoch Fehlermeldungen aufgetreten sein sollten, dann klicke auf die jeweilige Fehlermeldung im Meldungsfenster und vergleiche deine Eingaben mit dem Programmlisting. Korrigiere die aufgetretenen Fehler und compiliere das Programm erneut. Alte Hasen unter den Programmierern nennen diesen Vorgang eine Strafschleife…
Wenn keine Fehlermeldungen mehr auftauchen, dann ist es an der Zeit, unser erstes Programm zu testen. Drücke hierfür die Funktionstaste <F5> – es öffnet sich eine Kommandozeile:
Erwartungsgemäß gibt das Programm den Text „Hallo vom langweiligsten Programm der Welt!“ aus – und eine weitere, wichtige Information:
(program exited with code: 0)
Diese Meldung repräsentiert den Rückgabewert (später mehr dazu!) der Anwendung. Ein Kommandozeilen-Programm kann zu Diagnosezwecken beim Beenden unterschiedliche Codes an die Kommandozeile zurückgeben! Schließe nun die Kommandozeile durch Drücken einer beliebigen Taste.
hallo.cpp – Programmanalyse
Der Quellcode hallo.cpp mutet dir sicher noch sehr kryptisch an. Nehmen wir unser erstes Programm einmal genauer unter die Lupe und betrachten seine Bestandteile:
Zeile 1: Die Sequenz „/*“ leitet einen mehrzeiligen Kommentar ein, der in Zeile 4 mit der Sequenz „*/“ abgeschlossen wird. Alle, was zwischen diesen beiden Sequenzen steht, gilt als Kommentar und wird vom Compiler komplett ignoriert.
die Zeilen 2 und 3 enthalten einen kurzen, erklärenden Kommentar zum Programm.
Zeile 5 ist eine Leerzeile. Sie dient der Strukturierung des Programmcodes und damit der besseren Lesbarkeit.
Zeile 6: Die Angabe von #include veranlasst den Präprozessor (Bestandteil des Compilers) zum Einbinden einer Datei in den jeweiligen Quellcode. Die Präprozessor-Anweisung #include <iostream> bindet eine sogenannte System-Header-Datei – in diesem Fall enthält sie Definitionen und Funktionen der Ein-/Ausgabebibliothek für C++ und stellt u. a. den Ausgabestream cout für die Ausgabe von Texten in der Kommandozeile zur Verfügung. Im Gegensatz zu C besitzen System-Header-Dateien keinen Suffix. Sie werden innerhalb eines Paares spitzer Klammern aufgerufen, der Präprozessor sucht sie automatisch im Include-Verzeichnis des Compilers. Möchte man hingegen eigene Header-Dateien (Suffix per Konvention: .hpp oder .h) einbinden, so setzt man diese innerhalb eines Paares von Hochkommata (aka Anführungszeichen). Wird kein expliziter Pfad angegeben, so sucht der Präprozessor im aktuellen Verzeichnis:
Beispiel 1: #include "hallo_functions.hpp"
Beispiel 2: #include "D:\Projekte\my_functions.hpp"
Zeile 7: Funktionskopf der „Hauptfunktion“ main(), der Steuerung des Programmablaufs eines jeden C++-Programms. Funktionen bestehen grundsätzlich aus einem Funktionskopf mit Angabe der Datentypen für Rückgabewert und Funktionsparametern, dem Funktionsnamen, den in runde Klammern gefassten Funktionsparametern und einem zwischen geschweiften Klammern eingebetteten Funktionsrumpf, innerhalb dessen sich die Funktionslogik befindet – die genaue Verwendung des Begriffs „Datentyp“ klären wir noch. Die Funktion main() ist einzigartig im gesamten Quellcode und darf sich, im Gegensatz zu anderen Funktionen, nicht selbst aufrufen.
Zeile 8: Öffnende geschweifte Klammer des Funktionsrumpfes
Zeile 9: Anweisungen zur Ausgabe eines Textes und dessen Formatierung. Die Bestandteile im Einzelnen: std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl; Der Ausgabestream cout ist Bestandteil des Namensraums (aka namespace) std. Da wir es eingangs versäumt haben, dem Compiler diesen Namensraum mittels der Anweisung using namespace std; bekannt zu machen, müssen wir den Ausgabestream explizit unter Angabe seines Namensraums mit dem Präfix std:: aufrufen: std::cout. Das Präfix std::cout teilt dem Compiler mit, dass das Ausgabestream-Objekt cout im Namensraum der Standardbibliothek liegt.
Exkurs: Namensräume bieten eine Methode zur Vermeidung von Namenskonflikten in großen Projekten. Symbole, die innerhalb eines Namespace-Blocks deklariert sind, werden in einen benannten Bereich platziert, der verhindert, dass sie mit gleichnamigen Symbolen in anderen Bereichen verwechselt werden. Es sind mehrere Namespace-Blöcke mit demselben Namen zulässig. Alle Deklarationen innerhalb dieser Blöcke werden in dem benannten Bereich deklariert. Wir gehen später ausführlicher auf dieses Thema ein.
Der Verkettungsoperator << überträgt die auf ihn folgende Zeichenkette an das Ausgabestream-Objekt cout.
Die Zeichenkette (aka String) „Hallo vom langweiligsten Programm der Welt!“ folgt dem Verkettungsoperator und soll ausgegeben werden. Zeichenketten werden zwischen Hochkommata eingeschlossen und können Steuerzeichen enthalten – das ist in diesem Beispiel allerdings nicht der Fall.
Der auf die Zeichenkette folgende Verkettungsoperator bewirkt einen Zeilenvorschub durch Verknüpfung mit dem Manipulator endl.
Der Manipulator endl bewirkt einen Zeilenvorschub und leert den Ausgabestream. Hinweis: Würde man lediglich einen Zeilenvorschub erreichen wollen, so müsste man stattdessen das Steuerzeichen \n innerhalb der vorangegangenen Zeichenkette platzieren: ... << "Hallo vom langweiligsten Programm der Welt \n"
Das Semikolon schließt die zusammengesetzte Anweisung (aka „den Befehl“) ab und sorgt für die Ausführung. Unter C++ schließt man Anweisungen grundsätzlich mit einem Semikolon ab!
Zeile 10: Die Anweisung return 0; liefert den Wert Null an den Aufrufer (die Kommandozeile) zurück. Das Programm ist somit beendet.
Zeile 11: Schließende geschweifte Klammer des Funktionsrumpfes.
Das waren jetzt sehr viele Erklärungen und neue Begriffe auf einen Schlag! Lasse die Informationen ein Weilchen sacken und rekapituliere das Gelernte, bevor du mit dem nächsten Thema weitermachst.
Was geschieht beim Compilerlauf?
Die Kenntnis der genauen Abläufe während des Übersetzungsprozesses kann dir dabei helfen, Fehlermeldungen besser zu interpretieren und so einem Fehler schneller auf die Schliche zu kommen. Der Übersetzungsprozess erstreckt sich über vier Phasen – und in jeder Phase können spezifische Fehler auftreten.
Die vier Phasen des Übersetzungsprozesses:
Unser erstes lauffähiges Programm haben wir nun erstellt und seine Bestandteile besprochen. Gehen wir einen Schritt zurück und schauen uns den Prozess, den der Compiler durchläuft, wenn er dein Programm erstellt, einmal genauer an.
Das Verständnis dieser Abläufe ist deshalb wichtig, weil es verschiedene Arten von Fehlern gibt, die beim Schreiben von Code auftreten könnten. Es wird dir dabei helfen, eventuelle Fehler einzugrenzen und leichter aufzuspüren. Wenn ein Programm aus dem Quellcode erstellt wird, arbeiten vier Tools daran, bevor es sich um eine ausführbare Datei handelt: Der Präprozessor, der Compiler, der Assembler und der Linker.
Auch wenn es sich im Sprachjargon so eingebürgert hat, handelt es sich bei g++ genau genommen nicht wirklich um den Compiler, sondern viel mehr um eine Benutzer- schnittstelle, welche die Arbeit der einzelnen Compiler-Bestandteile koordiniert. Diese Schnittstelle leitet, in Abhängigkeit von übergebenen Parametern und im Quellcode hinterlegten Präprozessor-Anweisungen, die entsprechenden Phasen der Compilierung ein:
Phase 1: Der Präprozessor
Der Präprozessor nimmt den unverarbeiteten Quellcode als Eingabe entgegen und führt einige kleinere Bearbeitungen durch, bevor der von ihm erzeugte Code an den Compiler weitergeschickt wird. Er entfernt u.a. Kommentare und fügt den Inhalt von mit #include-Anweisungen eingebundenen Dateien in den von ihm erstellten Zwischencode ein. Es gibt weitere Präprozessor-Anweisungen, die wir zu einem späteren Zeitpunkt ausführlicher behandeln werden.
Phase 2: Der Compiler
Der Compiler übersetzt den C++-Code in Maschinensprache (Assembler). Assembler-Code ist viel, viel näher an den Anweisungen, die der Computer versteht dran und bleibt dabei für den Menschen lesbar. Der erzeugte Code ist spezifisch für den Prozessor, für den er geschrieben wird.
Phase 3: Der Assembler
Der Assembler erstellt aus dem vom Compiler erzeugten Assembler-Code Objektcode und legt diesen in Objektdateien, die eine .o-Erweiterung haben, ab. Objektcode besteht aus den tatsächlichen maschinenausführbaren Anweisungen, die vom Computer verwendet werden, um dein Programm auszuführen. Er ist jedoch noch nicht ganz ausführungsreif. Im gegenwärtigen Zustand gleichen die Objektdateien, aus denen Ihr Programm besteht, einer Reihe von Puzzlestücken, die erst noch zusammengesetzt werden müssen.
Phase 4: Der Linker
Der Linker fügt deine Objektdateien mit allen Bibliotheken, die du verwendest, zu einem ausführbaren Programm zusammen.
Der Entwicklungszyklus eines C++ Programms
Der vollständige Entwicklungszyklus eines C++ Programms umfasst noch mehr Aspekte, als bloß das Schreiben des Quelltextes und den Compilerlauf.
Am Anfang steht natürlich die Idee zum Programm und ihre Umsetzung in C++ – das Schreiben des Quelltextes.
Im zweiten Schritt wird der Quelltext durch einen Compilerlauf zu einem Object-Code übersetzt. Das kann auf Anhieb funktionieren – oder auch nicht.
Falls in diesem Stadium Compilerfehler auftreten, so muss deren Ursache im Quelltext gesucht und behoben werden. Diesen Vorgang nennt man Source Level Debugging. Anschließend erfolgt ein weiterer Compilerlauf.
Geht nun alles glatt, dann wird versucht, den erzeugte Object-Code durch den Linker um erforderliche Bibliotheken zu erweitert und zu einem ausführbaren Programm zu „binden“.
Falls der Linker Fehler meldet, so müssen die Ursachen erneut im Quelltext gesucht und ein neuer Compilerlauf angestoßen werden. Ist dieser dann erfolgreich, so wird das fertige Programm erzeugt und kann jetzt auf Laufzeitfehler getestet werden. Dazu startet man das Programm und vergleicht sein Verhalten und seine Ausgaben mit den bei Programmlegung festgelegten Erwartungen.
Laufzeitfehler führen zum Absturz des ausgeführten Programms, zu falschen Ergebnissen oder zu nicht vorhersehbarem Verhalten des Programms. Die Ursachen dafür können sehr unterschiedlich sein – beispielsweise wenn Variablen mit falschen/inkonsistenten Daten überschrieben oder gefüllt werden, die in nachfolgenden Befehlen zu Fehlern führen. Laufzeitfehler sind deutlich schwerer aufzuspüren, als einfache Syntaxfehler. In der Regel kommt dann ein Debugger zum Einsatz, mit dem man das Verhalten von Speicheradressen und Variableninhalten zur Laufzeit mitverfolgen kann. GCC stellt hierfür den gdb Debugger zur Verfügung.
Ein Programm ist erst dann als vollständig entwickelt anzusehen, wenn es fehlerfrei läuft.
Um mit C++ programmieren zu können, brauchst du eigentlich nur einen auf deinem Betriebssystem lauffähigen Compiler für C++ und einen entsprechenden Texteditor. Dein Texteditor sollte unbedingt visuelle Zeilennummerierung und die Syntax-Hervorhebung (aka Highlighting) für C++ unterstützen, das macht das Schreiben von Programmen und die Fehlersuche wesentlich einfacher.
Unter Linux bist du von vorn herein fein raus – das OS bringt die GNU Compiler Collection (GCC) und diverse Texteditoren mit oder ohne GUI bereits mit. Du brauchst die entsprechenden Pakete nur mit dem Paketmanager deiner Linux-Distribution zu installieren. Kostet keinen Cent.
Auch unter Windows stehen diverse Compiler-Systeme und Editoren zur Verfügung – neben wahren Monstern wie dem Microsoft Visual Studio u. a. auch die GNU Compiler Collection GCC. Empfehlenswerte Text-Editoren sind u.a. Geany, Notepad++ und die Entwicklungsumgebung Code::Blocks.
Auf einem Macunter OS X musst du zunächst erst XCode installieren. Die Entwicklungsumgebung bringt alle nötigen Bestandteile für die Programmierung mit C++ mit.
Betrachtungen zur Entwicklungsumgebung
Um Programme in C++ schreiben zu können, benötigst du also eine Entwicklungs- umgebung und die besteht in ihrer einfachsten Form aus zwei grundlegenden Komponenten: Einem Compilersystem für C++ und einem dedizierten Texteditor zur Erfassung der Quelltexte.
Beides kostenlos zu beschaffen ist heute kein Problem. Unter Linux steht alles, was du zum Programmieren benötigst, ohnehin im Paketmanager der jeweiligen Distribution zur Verfügung. Für andere Betriebssysteme existieren vorkonfigurierte Lösungen, wie z. B. Microsoft Visual Studio Community Edition unter Windows oder XCode auf dem Mac. Solche Komplettlösungen bieten neben vielen Vorteilen allerdings auch einige gravierende Nachteile für Einsteiger. Sie sind zunächst unübersichtlich, aufwendig zu konfigurieren, erfordern zusätzliche Einarbeitungszeit und lenken dich so erst mal von der eigentlichen Aufgabe ab: Programmieren lernen!
Für dieses Tutorial werden wir uns eine maßgeschneiderte eigene, zukunftssichere Entwicklungsumgebung für C++ zusammenstellen, die nicht nur den Bedürfnissen eines Einsteigers gerecht wird, sondern später auch das Programmieren von Anwendungen mit grafischer Benutzeroberfläche erlaubt.
1 – Der Compiler
Um einen Quelltext in ein lauffähiges Programm zu übersetzen, bedarf es eines C++-Compilers. Ich habe mich hier für die C/C++-Komponenten aus der GNU Compiler Collection (GCC – GNU gcc/g++) entschieden – diese sind stets aktuell, mächtig, erfüllen annähernd die neuesten Sprachstandards und stehen für alle gängigen Betriebssysteme zur Verfügung. Insgesamt unterstützt die GCC mehr als 60 Plattformen. Die Programme der GCC sind ein gut etablierter Standard für Programmierer und werden auch im professionellen Umfeld entsprechend gern und häufig eingesetzt.
GNU Compiler Collection herunterladen
GNU gcc/g++findet man in verschiedenen Varianten im Internet. Auch wenn es ein wenig Overhang bedeutet, werden wir in diesem Tutorial mit Hinblick auf die spätere Entwicklung von Programmen mit grafischer Benutzeroberfläche (nicht Bestandteil dieses Tutorials!) die Installation zusammen mit dem Qt Frameworkund dem Qt-Creator vornehmen.
Unter Linux installiere einfach alle Komponenten für Qt5, Qt6 und den Qt-Creator über den Paketmanager deiner Distribution. Für andere Betriebssysteme gilt:
Melde dich im Installer mit deinen Zugangsdaten an und klicke auf <weiter>
Setze die Haken für die Checkboxen wie im folgenden Bild: Klicke auf <weiter>
Durchlaufe mit die Installationsroutine bis zum Punkt „Benutzerdefinierte Installation“. Bestimme den Speicherort für die Installation von Qt und klicke auf <weiter>
Setze die Haken bei „Qt Creator“, „Additional Libraries“ und in der aktuellsten Qt6 Release Version den Haken bei „MinGW 11.2.0 64-bit“.
Gib im Suchfeld „Qt 5“ ein. Unter dem Eintrag „Qt 5.15.2“ selektiere mindestens den Eintrag „MinGW 8.1.0 64-bit“ und die Einträge für die zusätzlichen Bibliotheken:
Unter „Developer and Designer Tools“ selektiere die Einträge „Qt Creator“, „MinGW 13.0.1 64-bit“, „MinGW 11.1.0 64-bit“, „MinGW 8.1.0 64-bit“, „CMake“ und „Ninja“.
Zum Start der Installation klicke auf und fasse dich in Geduld…
Einrichtung des Compilers
Um den Compiler von der Kommandozeile aus erreichen zu können ist es notwendig, die PATH Variable deines Betriebssystems entsprechend um den Pfad zum Compiler zu erweitern. Unter Linux geschieht das automatisch bei der Installation von gcc, unter anderen Betriebssystemen musst du die Anpassung selbst vornehmen.
Angenommen, du befindest dich unter Windows, bist der Installationsanleitung gefolgt und hast Qt nach C:\Qt installiert. Die aktuell höchste installierte Version von MinGW (gcc) findest Du dann unter C:\Qt\Tools\mingw1310_64.
Öffne den Dialog zur Einstellung von Umgebungsvariablen, selektiere „PATH“ und erweitere die Variable um die aus dem folgenden Bild ersichtlichen Einträge:
Bestätige den Dialog und alle übergeordneten Instanzen, öffne eine neue Kommandozeile und teste deine Einstellungen durch Eingabe von gcc -v:
Dein Compiler-System sollte nun einsatzbereit sein. Für das Setzen von Systemvariablen unter anderen Betriebssystemen konsultiere bitte das entsprechende Handbuch.
Verwenden des Compilers
Am Einfachsten ist es, den Compiler über entsprechende Befehle aus dem Editor heraus zu steuern – und das ist auch die bevorzugt Vorgehensweise in diesem Tutorial. Trotzdem kann es nicht schaden, wenn du weißt, wie man den Compiler auch auf der Kommandozeile bedienen kann.
Für die Übersetzung von C++-Quelltexten verwenden wir GNU g++, das C++-Compiler Backend der GNU Compiler Collection. Es wird über diverse Schalter gesteuert, die sein Verhalten regeln. Hier eine kurze Aufstellung der wichtigsten Schalter:
-Wall (Warn all) sorgt dafür, dass der Compiler neben Fehlern auch auf sämtliche Warnungen bei der Übersetzung eines Programmes reagiert und diese ausgibt
-v (verbose) bewirkt eine sehr detaillierte Ausgabe von Compilermeldungen
-std= <Bezeichner> bewirkt die Verwendung eines bestimmten, definierten Compilerstandards
-s (strip) bewirkt die Optimierung der Größe des erzeugten Programms
-g, -ggdb (gnudebug) fügt dem erzeugten Programm sogenannten Debug-Code hinzu – das Programm lässt sich so mit dem Debugger (Werkzeug zur Fehlersuche) gdb aus der GNU Compiler Collection auf Fehler überprüfen
-o (output) speichert das übersetzte Programm unter einem frei wählbaren Namen
-l (Library) bindet eine zusätzliche Linker-Bibliothek ein. Häufig verwendet wird z. B. -lm zur Einbindung der mathematischen Bibliothek für arrithmetische CoProzessoren (FPU)
-O (optimize) bewirkt die Optimierung des zu übersetzenden Programms, wobei der Parameter für die Optimierungsstufe steht. Üblich ist z.B. -O3. Optimierungen sollten nur bei einem vorher ausgiebig getesteten, für die Veröffentlichung bestimmten Programm zugeschaltet werden!
Zum Compilieren eines Programms auf der Kommandozeile musst du dich in dem Verzeichnis befinden, in dem der zugehörige Quelltext gespeichert ist. Der übliche Aufruf von g++ für die Programme in diesem Tutorial lautet dann: g++ -Wall -std=c++17 -o meinProgramm meinCode.cpp
Dabei gibt g++ sämtliche auftretenden Fehlermeldungen und Warnungen unter Verwendung des ISO/ANSI-Standards c++17 auf der Kommandozeile aus und erstellt aus dem Quelltext meinCode.cpp das lauffähige Programm meinProgramm. Unter DOS/Windows wird automatisch noch der Suffix .exe an den Programmnamen angehängt. Das fertig übersetzte Programm befindet sich danach im gleichen Verzeichnis wie der zugehörige Quellcode und kann durch
meinProgramm + <Eingabetaste>
zur Ausführung gebracht werden.
Der Compiler besitzt noch viele weitere Schalter und Optionen. Außerdem enthält die GNU Compiler Collection weitere nützliche Tools und Hilfsprogramme. Eine vollständige Beschreibung findest Du in den Handbüchern unter https://gcc.gnu.org/onlinedocs/gcc-13.3.0/gcc/
2 – Der Editor
Zum Schreiben von Programmen brauchst Du, wie bereits gesagt einen Editor, der deine Quelltexte als einfache ASCII-Dateien speichern kann. Grundsätzlich könnte man hierfür nun den Qt-Creator oder andere Speichermonster wie Visual Studio Code, Word oder LibreOffice Writer mit speziellen Speicheroptionen einsetzen – jedoch ist es deutlich angenehmer, auf einen Editor zurück zu greifen, der dich nicht ablenkt, Nützlichkeiten wie Syntax Highlighting, Code Folding und Auto-Vervollständigung beherrscht und am Besten auch gleich noch den Compiler anzusprechen vermag. Die Puristen unter den Programmierern nehmen hierfür GNU Emacs, vi oder nano unter Linux, wir allerdings wollen es in diesem Tutorial etwas bequemer haben.
Es existiert eine mehr oder minder reiche Auswahl an solchen Editoren für die verschiedenen Betriebssysteme. In diesem Buch gehe ich davon aus, dass du den quelloffenen Editor „Geany“ verwendest – er erfüllt alle oben genannten Kriterien und ist für Linux, Windows und MacOS kostenlos erhältlich.
Geany herunterladen und installieren
Unter Linux ist der Editor bereits Bestandteil vieler Distributionen – installiere das Programm einfach über den Paketmanager der von dir verwendeten Linux-Distribution. Für andere gebräuchliche Betriebssysteme gilt: Geany und seine Zusatzkomponenten kannst du hier für dein Betriebssystem herunterladen: https://www.geany.org/download/releases/ Um Geany zu installieren genügt es, den jeweiligen Installer für das von dir verwendete Betriebssystem zu starten.
Geany konfigurieren
Geany kommt bereits vorkonfiguriert daher, unterstützt viele gängige Programmier- sprachen und erkennt selbstständig, mit Welcher du gerade arbeitest. Dabei lässt sich der jeweilige Befehlssatz zur Ansteuerung des Compilers aber noch nachjustieren. Klicke dazu im Menü „Erstellen“ auf den Eintrag „Kommandos zum Erstellen konfigurieren“ – es erscheint der folgende Dialog:
Die Compiler gcc und g++ übersetzen Programme standardmäßig mit gnu99, einer älteren Vorgabe für C/C++ mit einigen zusätzlichen Besonderheiten der GNU Compiler Collection. In diesem Buch wollen wir aber mit einem fortgeschrittenen, relativ aktuellen Sprachstandard arbeiten, wie er in den Normen c++14 und c++17 für ISO/ANSI C++ definiert ist.
Der Schalter -std veranlasst gcc/g++ dazu, einen anderen als den vorgegebenen Sprachstandard zu verwenden. Trage deshalb im Konfigurationsdialog hinter allen Vorkommen von g++ -Wall den Schalter -std=c++17 ein.
Der Schalter -Wall (Warn all) sorgt dafür, dass der Compiler Warnungen und Fehlermeldungen ausgibt. Das ist besonders nützlich für die Fehlersuche im Quelltext. Besonders geschwätzig wird der Compiler, wenn du zusätzlich noch den Schalter -v (verbose) einfügst – allerdings wird die Ausgabe der Meldungen dann schnell unübersichtlich.
Geany verwenden
Geany zeichnet sich durch Schlichtheit und Funktionalität aus – alles ist intuitiv und leicht erreichbar. Das folgende Bild illustriert den Aufbau des Editors:
Texteingabefenster: Hier gibst du deine Programme ein.
Meldungsfenster: Hier erfolgt die Ausgabe von Compilermeldungen. Falls bei der Übersetzung ein Fehler oder eine Warnung aufgetreten ist, so kannst du diese anklicken – die Schreibmarke springt dann im Texteingabefenster auf die vermutete Stelle, an der ein Problem aufgetreten ist.
Seitenleiste: Hier listet der Editor Klassen, Funktionen, Strukturen und andere Elemente von C++ auf. Durch einen Klick auf einen Eintrag springt die Schreibmarke zur entsprechenden Stelle im Texteingabefenster.
Die Arbeit mit dem Editor gestaltet sich denkbar einfach:
Programme schreiben: Gib deinen Quelltext im Texteingabefenster ein und speichere ihn unter einem aussagekräftigen Namen mit der Dateiendung .cpp ab.
Übersetzung anstoßen: Drücke die Funktionstaste <F9> , um den Quelltext compilieren zu lassen. Veränderungen am Quelltext werden dabei automatisch gespeichert. Falls du den Quelltext noch nicht abgespeichert hast, so musst du das vor dem ersten Compilerlauf nachholen.
Programm ausführen: Drücke die Funktionstaste <F5>, um das fertige Programm zu starten.