In diesem Teil des C++ Tutorials beschäftigen wir uns mit Techniken zur Speicherung unserer Quelltexte und dem Schreiben und Übersetzen derselben. Bevor es richtig losgeht, noch einige Vorüberlegungen zur Organisation der anfallenden Daten:
- Betrachte ab sofort jedes Programm, das du eingibst, als eigenständiges Projekt. Lege dir zu diesem Zweck zunächst ein Sammelverzeichnis an, in welchem du dann wiederum Ordner für die eigentlichen Projekte erstellst.
Beispiel: D:\Einsteigerseminar - Jedes Projekt erhält seinen eigenen Ordner, in dem alle relevanten Daten zum Projekt gespeichert werden. Dies ist das Arbeitsverzeichnis des jeweiligen Projekts!
Beispiel 1: D:\Einsteigerseminar\001_Hallo
Beispiel 2: D:\Einsteigerseminar\002_Kommentare
Relevante Daten können z. B. sein:
- C++-Quelltext für das eigentliche Programm (Suffix: .cpp)
- C++-Quelltexte, die vom Hauptprogramm eingebunden werden, um weitere Fähigkeiten zum Programm hinzu zu fügen – sog. „Header-Dateien“ (Suffix: .hpp)
- Makefiles (Dateien mit Compileranweisungen zur Übersetzung des Programms, kein Suffix)
- Vom Programm zu speichernde oder zu lesende Datendateien (Suffix: frei wählbar)
- Grafiken (Suffix: .png | .jpg | .ico, usw …)
- Textdatei mit einer Beschreibung des Programmes und/oder einer TODO-Liste (Suffix: .txt)
Für unser erstes Projekt könnte das dann z. B. so aussehen:
D:\Einsteigerseminar\001_Hallo
hallo.cpp
hallo_functions.hpp
hallo.ico
Makefile_release
Makefile_debug
README_Hallo.txt
„Hallo, Welt“ – das erste C++ Programm
Erstelle zunächst in deinem Sammelverzeichnis für Projekte den Unterordner 001_Hallo. Starte dann den Editor (Geany) und speichere das (noch leere) Programm unter dem Namen hallo.cpp in diesem Ordner ab. Gib danach den folgenden Quellcode (ohne Zeilennummern!) ein und achte darauf, alles so abzutippen, wie ich es hier notiert habe:
/*
C++ Einsteiger Tutorial
Source: hallo.cpp
*/
#include <iostream>
int main()
{
std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl;
return 0;
}Drücke nun die Funktionstaste , um das Programm zu compilieren. Wenn du alles richtig gemacht hast, meldet der Compiler:
g++ -Wall -std=c++17 -o "hallo" "hallo.cpp" Kompilierung erfolgreich beendet.
Falls jedoch Fehlermeldungen aufgetreten sein sollten, dann klicke auf die jeweilige Fehlermeldung im Meldungsfenster und vergleiche deine Eingaben mit dem Programmlisting. Korrigiere die aufgetretenen Fehler und compiliere das Programm erneut. Alte Hasen unter den Programmierern nennen diesen Vorgang eine Strafschleife…
Wenn keine Fehlermeldungen mehr auftauchen, dann ist es an der Zeit, unser erstes Programm zu testen. Drücke hierfür die Funktionstaste <F5> – es öffnet sich eine Kommandozeile:
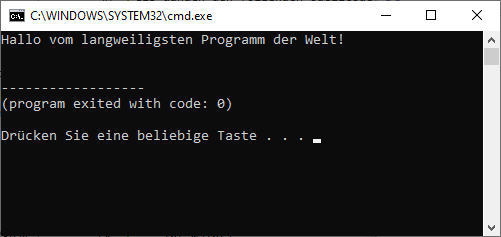
Erwartungsgemäß gibt das Programm den Text „Hallo vom langweiligsten Programm der Welt!“ aus – und eine weitere, wichtige Information:
(program exited with code: 0)
Diese Meldung repräsentiert den Rückgabewert (später mehr dazu!) der Anwendung. Ein Kommandozeilen-Programm kann zu Diagnosezwecken beim Beenden unterschiedliche Codes an die Kommandozeile zurückgeben! Schließe nun die Kommandozeile durch Drücken einer beliebigen Taste.
hallo.cpp – Programmanalyse
Der Quellcode hallo.cpp mutet dir sicher noch sehr kryptisch an. Nehmen wir unser erstes Programm einmal genauer unter die Lupe und betrachten seine Bestandteile:
- Zeile 1: Die Sequenz „/*“ leitet einen mehrzeiligen Kommentar ein, der in Zeile 4 mit der Sequenz „*/“ abgeschlossen wird. Alle, was zwischen diesen beiden Sequenzen steht, gilt als Kommentar und wird vom Compiler komplett ignoriert.
- die Zeilen 2 und 3 enthalten einen kurzen, erklärenden Kommentar zum Programm.
- Zeile 5 ist eine Leerzeile. Sie dient der Strukturierung des Programmcodes und damit der besseren Lesbarkeit.
- Zeile 6: Die Angabe von #include veranlasst den Präprozessor (Bestandteil des Compilers) zum Einbinden einer Datei in den jeweiligen Quellcode. Die
Präprozessor-Anweisung #include <iostream> bindet eine sogenannte System-Header-Datei – in diesem Fall enthält sie Definitionen und Funktionen der
Ein-/Ausgabebibliothek für C++ und stellt u. a. den Ausgabestream cout für die Ausgabe von Texten in der Kommandozeile zur Verfügung. Im Gegensatz zu C besitzen System-Header-Dateien keinen Suffix. Sie werden innerhalb eines Paares spitzer Klammern aufgerufen, der Präprozessor sucht sie automatisch im Include-Verzeichnis des Compilers. Möchte man hingegen eigene Header-Dateien (Suffix per Konvention: .hpp oder .h) einbinden, so setzt man diese innerhalb eines Paares von Hochkommata (aka Anführungszeichen). Wird kein expliziter Pfad angegeben, so sucht der Präprozessor im aktuellen Verzeichnis:
Beispiel 1: #include "hallo_functions.hpp"
Beispiel 2: #include "D:\Projekte\my_functions.hpp"- Zeile 7: Funktionskopf der „Hauptfunktion“ main(), der Steuerung des Programmablaufs eines jeden C++-Programms. Funktionen bestehen grundsätzlich aus einem Funktionskopf mit Angabe der Datentypen für Rückgabewert und Funktionsparametern, dem Funktionsnamen, den in runde Klammern gefassten Funktionsparametern und einem zwischen geschweiften Klammern eingebetteten Funktionsrumpf, innerhalb dessen sich die Funktionslogik befindet – die genaue Verwendung des Begriffs „Datentyp“ klären wir noch. Die Funktion main() ist einzigartig im gesamten Quellcode und darf sich, im Gegensatz zu anderen Funktionen, nicht selbst aufrufen.
- Zeile 8: Öffnende geschweifte Klammer des Funktionsrumpfes
- Zeile 9: Anweisungen zur Ausgabe eines Textes und dessen Formatierung. Die Bestandteile im Einzelnen:
std::cout << "Hallo vom langweiligsten Programm der Welt!" << std::endl;Der Ausgabestream cout ist Bestandteil des Namensraums (aka namespace) std. Da wir es eingangs versäumt haben, dem Compiler diesen Namensraum mittels der Anweisung using namespace std; bekannt zu machen, müssen wir den Ausgabestream explizit unter Angabe seines Namensraums mit dem Präfix std:: aufrufen: std::cout. Das Präfix std::cout teilt dem Compiler mit, dass das Ausgabestream-Objekt cout im Namensraum der Standardbibliothek liegt.
- Exkurs: Namensräume bieten eine Methode zur Vermeidung von Namenskonflikten in großen Projekten. Symbole, die innerhalb eines Namespace-Blocks deklariert sind, werden in einen benannten Bereich platziert, der verhindert, dass sie mit gleichnamigen Symbolen in anderen Bereichen verwechselt werden. Es sind mehrere Namespace-Blöcke mit demselben Namen zulässig. Alle Deklarationen innerhalb dieser Blöcke werden in dem benannten Bereich deklariert. Wir gehen später ausführlicher auf dieses Thema ein.
- Der Verkettungsoperator << überträgt die auf ihn folgende Zeichenkette an das Ausgabestream-Objekt cout.
- Die Zeichenkette (aka String) „Hallo vom langweiligsten Programm der Welt!“ folgt dem Verkettungsoperator und soll ausgegeben werden. Zeichenketten werden zwischen Hochkommata eingeschlossen und können Steuerzeichen enthalten – das ist in diesem Beispiel allerdings nicht der Fall.
- Der auf die Zeichenkette folgende Verkettungsoperator bewirkt einen Zeilenvorschub durch Verknüpfung mit dem Manipulator endl.
- Der Manipulator endl bewirkt einen Zeilenvorschub und leert den Ausgabestream. Hinweis: Würde man lediglich einen Zeilenvorschub erreichen wollen, so müsste man stattdessen das Steuerzeichen \n innerhalb der vorangegangenen Zeichenkette platzieren:
... << "Hallo vom langweiligsten Programm der Welt \n" - Das Semikolon schließt die zusammengesetzte Anweisung (aka „den Befehl“) ab und sorgt für die Ausführung. Unter C++ schließt man Anweisungen grundsätzlich mit einem Semikolon ab!
- Zeile 10: Die Anweisung return 0; liefert den Wert Null an den Aufrufer (die Kommandozeile) zurück. Das Programm ist somit beendet.
- Zeile 11: Schließende geschweifte Klammer des Funktionsrumpfes.
Das waren jetzt sehr viele Erklärungen und neue Begriffe auf einen Schlag! Lasse die Informationen ein Weilchen sacken und rekapituliere das Gelernte, bevor du mit dem nächsten Thema weitermachst.
Was geschieht beim Compilerlauf?
Die Kenntnis der genauen Abläufe während des Übersetzungsprozesses kann dir dabei helfen, Fehlermeldungen besser zu interpretieren und so einem Fehler schneller auf die Schliche zu kommen. Der Übersetzungsprozess erstreckt sich über vier Phasen – und in jeder Phase können spezifische Fehler auftreten.
Die vier Phasen des Übersetzungsprozesses:
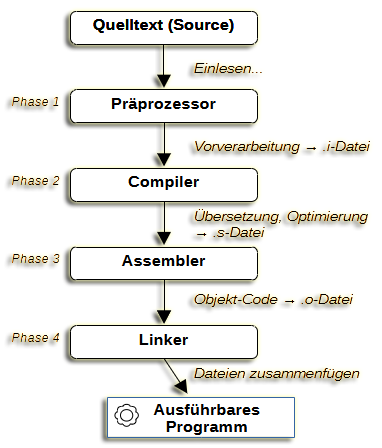
Unser erstes lauffähiges Programm haben wir nun erstellt und seine Bestandteile besprochen. Gehen wir einen Schritt zurück und schauen uns den Prozess, den der Compiler durchläuft, wenn er dein Programm erstellt, einmal genauer an.
Das Verständnis dieser Abläufe ist deshalb wichtig, weil es verschiedene Arten von Fehlern gibt, die beim Schreiben von Code auftreten könnten. Es wird dir dabei helfen, eventuelle Fehler einzugrenzen und leichter aufzuspüren. Wenn ein Programm aus dem Quellcode erstellt wird, arbeiten vier Tools daran, bevor es sich um eine ausführbare Datei handelt: Der Präprozessor, der Compiler, der Assembler und der Linker.
Auch wenn es sich im Sprachjargon so eingebürgert hat, handelt es sich bei g++ genau genommen nicht wirklich um den Compiler, sondern viel mehr um eine Benutzer- schnittstelle, welche die Arbeit der einzelnen Compiler-Bestandteile koordiniert. Diese Schnittstelle leitet, in Abhängigkeit von übergebenen Parametern und im Quellcode hinterlegten Präprozessor-Anweisungen, die entsprechenden Phasen der Compilierung ein:
Phase 1: Der Präprozessor
Der Präprozessor nimmt den unverarbeiteten Quellcode als Eingabe entgegen und führt einige kleinere Bearbeitungen durch, bevor der von ihm erzeugte Code an den Compiler weitergeschickt wird. Er entfernt u.a. Kommentare und fügt den Inhalt von mit #include-Anweisungen eingebundenen Dateien in den von ihm erstellten Zwischencode ein. Es gibt weitere Präprozessor-Anweisungen, die wir zu einem späteren Zeitpunkt ausführlicher behandeln werden.
Phase 2: Der Compiler
Der Compiler übersetzt den C++-Code in Maschinensprache (Assembler). Assembler-Code ist viel, viel näher an den Anweisungen, die der Computer versteht dran und bleibt dabei für den Menschen lesbar. Der erzeugte Code ist spezifisch für den Prozessor, für den er geschrieben wird.
Phase 3: Der Assembler
Der Assembler erstellt aus dem vom Compiler erzeugten Assembler-Code Objektcode und legt diesen in Objektdateien, die eine .o-Erweiterung haben, ab. Objektcode besteht aus den tatsächlichen maschinenausführbaren Anweisungen, die vom Computer verwendet werden, um dein Programm auszuführen. Er ist jedoch noch nicht ganz ausführungsreif. Im gegenwärtigen Zustand gleichen die Objektdateien, aus denen Ihr Programm besteht, einer Reihe von Puzzlestücken, die erst noch zusammengesetzt werden müssen.
Phase 4: Der Linker
Der Linker fügt deine Objektdateien mit allen Bibliotheken, die du verwendest, zu einem ausführbaren Programm zusammen.
Der Entwicklungszyklus eines C++ Programms
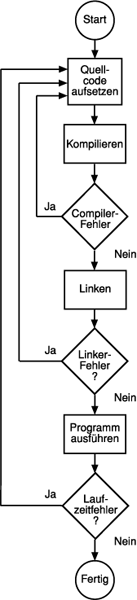
Der vollständige Entwicklungszyklus eines C++ Programms umfasst noch mehr Aspekte, als bloß das Schreiben des Quelltextes und den Compilerlauf.
Am Anfang steht natürlich die Idee zum Programm und ihre Umsetzung in C++ – das Schreiben des Quelltextes.
Im zweiten Schritt wird der Quelltext durch einen Compilerlauf zu einem Object-Code übersetzt. Das kann auf Anhieb funktionieren – oder auch nicht.
Falls in diesem Stadium Compilerfehler auftreten, so muss deren Ursache im Quelltext gesucht und behoben werden. Diesen Vorgang nennt man Source Level Debugging. Anschließend erfolgt ein weiterer Compilerlauf.
Geht nun alles glatt, dann wird versucht, den erzeugte Object-Code durch den Linker um erforderliche Bibliotheken zu erweitert und zu einem ausführbaren Programm zu „binden“.
Falls der Linker Fehler meldet, so müssen die Ursachen erneut im Quelltext gesucht und ein neuer Compilerlauf angestoßen werden. Ist dieser dann erfolgreich, so wird das fertige Programm erzeugt und kann jetzt auf Laufzeitfehler getestet werden. Dazu startet man das Programm und vergleicht sein Verhalten und seine Ausgaben mit den bei Programmlegung festgelegten Erwartungen.
Laufzeitfehler führen zum Absturz des ausgeführten Programms, zu falschen Ergebnissen oder zu nicht vorhersehbarem Verhalten des Programms. Die Ursachen dafür können sehr unterschiedlich sein – beispielsweise wenn Variablen mit falschen/inkonsistenten Daten überschrieben oder gefüllt werden, die in nachfolgenden Befehlen zu Fehlern führen. Laufzeitfehler sind deutlich schwerer aufzuspüren, als einfache Syntaxfehler. In der Regel kommt dann ein Debugger zum Einsatz, mit dem man das Verhalten von Speicheradressen und Variableninhalten zur Laufzeit mitverfolgen kann. GCC stellt hierfür den gdb Debugger zur Verfügung.
Ein Programm ist erst dann als vollständig entwickelt anzusehen, wenn es fehlerfrei läuft.
[Inhaltsverzeichnis] | [zurück] | [vorwärts]